
Het concept ‘deel-economie’ is een eigen leven gaan leiden – niet alleen bij consumenten en slimme ondernemers, maar ook bij bestuurders en beleidsmakers. Naïevelingen denken dat de deeleconomie een sociaal verschijnsel is waar mensen elkaar belangeloos helpen door te delen. Er zijn mooie initiatieven waarvoor dat geldt, maar de grootste namen uit de ‘deeleconomie’ zijn gewoon bedrijven.
Deeleconomie is hip en hot. Niet omdat iedereen er aan doet, maar omdat het succes van enkele grote spelers de hoofden op hol brengt. De deeleconomie zorgt voor innovatie, welvaart, werkgelegenheid, een beter milieu en draagt bij aan een kleinere overheid. Althans, dat roept de VVD in Amsterdam, die vindt dat de stad nog wel een stapje verder kan gaan om de volle potentie van de deeleconomie in Amsterdam maximaal benutten. Ondernemers die met deeleconomie-initiatieven van start willen, ervaren regeldruk, aldus Marja Ruigrok en Marianne Poot (beiden VVD), maar: “goede ondernemers zijn vindingrijk en het is dus logisch dat ze steeds opnieuw manieren verzinnen om de door de overheid opgelegde regels te omzeilen.” Blijkbaar zijn de juridische conflicten die Uber veroorzaakt en de klachten over Airbnb een verschijnsel dat onderdeel is van deeleconomie.
Voor de volledigheid: ook Ruigrok en Poot vinden dat er keihard worden opgetreden tegen overlast: “de overheid moet wel haar verantwoordelijkheid nemen.” Toch stellen Poot en Ruigrok ook impliciet dat consumenten in de deeleconomie geen bescherming meer nodig hebben – daar zorgt de zelfregulering voor. Vroeger bleef slechte service of een ondermaats product vaak onopgemerkt,” aldus het tweetal, maar nu is alles een stuk transparanter dankzij het internet en apps. Ruigrok en Poot stellen ook dat er met het schrappen van overbodig geworden regels en vergunningen een gelijk speelveld ontstaat. Maar sommige regels zijn toch echt nodig – kijk naar Airbnb – en ook ‘gewone’ taxichauffeurs weten beter dan Poot en Ruigrok dat Uber juist geen level playing field wil. Uber heeft al meerdere malen aangegeven zich niets aan te trekken van regels, laat staan van opgelegde boetes. En ja, de deeleconomie is goed voor de innovatie, stellen Ruigrok en Poot. Ik denk dat beiden geen idee hebben hoeveel bejaarde deelauto’s er via Snappcar rondrijden door de stad. Overigens wilde Snappcar zelf deze vraag ook niet beantwoorden.
Kortom, dit VVD-duo heeft er weinig van begrepen. Gewone economie en deeleconomie worden door elkaar gehaald; regels en zelfregulering zijn blijkbaar uitwisselbaar en rankings zouden zorgen voor meer transparantie. Poot en Ruigrok zouden beter moeten weten: het paradepaardje van de deeleconomie, Airbnb, heeft helemaal niets met deeleconomie te maken. In tegendeel, het is gewoon een verdienmodel voor zowel de verhuurders als het bedrijf zelf. Eind 2015 stonden er volgens Airbnb meer dan 14.000 Amsterdamse appartementen en kamers te huur. Goed voor de economie? Ja, als wel je kijkt naar de baten: Airbnb-verhuurders in Amsterdam verdienden in dat jaar totaal zo’n 100 miljoen euro, gemiddeld 7.000 euro per Airbnb-adres. Airbnb rekent zowel bij verhuurder als huurder 3 procent servicekosten. Sinds februari 2015 draagt Airbnb ook toeristenbelasting af aan de gemeente: in dat eerste jaar goed voor circa 5,5 miljoen euro.
 Dat verhuren gaat niet altijd van een leien dakje. Stalking door potentiële huurders, hacking van je Airbnb-account, schade aan je huis en/of spullen, en geconfronteerd worden met meer huurders dan zich hebben aangemeld: het waren de verhuurders zelf die met deze ervaringen naar voren kwamen tijdens een voorlichtingssessie op 14 april voor bestaande en nieuwe verhuurders in Amsterdam. Een andere, meermalen geuite klacht over het Airbnb-platform: als je als verhuurder een potentiële huurder weigert, zak je in ranking. De onvrede hierover benadrukt het belang van het verdienmodel.
Dat verhuren gaat niet altijd van een leien dakje. Stalking door potentiële huurders, hacking van je Airbnb-account, schade aan je huis en/of spullen, en geconfronteerd worden met meer huurders dan zich hebben aangemeld: het waren de verhuurders zelf die met deze ervaringen naar voren kwamen tijdens een voorlichtingssessie op 14 april voor bestaande en nieuwe verhuurders in Amsterdam. Een andere, meermalen geuite klacht over het Airbnb-platform: als je als verhuurder een potentiële huurder weigert, zak je in ranking. De onvrede hierover benadrukt het belang van het verdienmodel.
Amsterdam wil een gastvrije stad zijn en vakantieverhuur is een welkome aanvulling op andere voorzieningen, maar: “woningen zijn in de eerste plaats bedoeld als woning,” aldus Laila Frank, werkzaam als projectcoördinator toeristische verhuur voor de gemeente Amsterdam, ook aanwezig bij de voorlichtingsbijeenkomst van Airbnb. Vakantieverhuur is in Amsterdam beperkt toegestaan en aan regels gebonden die betrekking hebben op veiligheid en overlastbeperking. De belangrijkste regels van dit moment: je moet zelf in de woning wonen, vakantieverhuur mag maximaal 60 dagen per jaar en voor maximaal 4 personen per keer. Verder is vakantieverhuur in sociale huurwoningen verboden. Dit beleid, waar ook de fel bekritiseerde MOU met Airbnb onderdeel van was, is twee jaar geleden voor het eerst vastgesteld door Gemeente Amsterdam.
Volgens Frank is de gemeenteraad op dit moment erg kritisch over de groei van vakantieverhuur. Ten opzichte van het voorgaande jaar is het aantal klachten in 2015 verdubbeld en er is in zowel bestuur als onder bewoners veel te doen over de toegenomen belasting van de stad door het toerisme. Het beleid wordt nu geëvalueerd en Amsterdam, dat blijft vasthouden aan het samenwerkingsmodel met de verschillende platforms, streeft naar “een betere deal met Airbnb” dan er tot nu toe was. De gemeente heeft vooral behoefte aan “grip op de vakantieverhuur. Ze zijn een schakel tussen vraag en aanbod, maar geven geen data,” zei Frank. Dat gebrek aan transparantie bemoeilijkt handhaving. Het werken met vergunningen past niet in het beleid en maakt de zaak gecompliceerder: Amsterdam beschouwt vakantieverhuur door particulieren als een “lolletje”, met vergunningen kom je in de buurt van bedrijfsmatige activiteiten. Ook Shortstay – oorspronkelijk bedoeld als oplossingen voor expats – is alleen toegestaan met een vergunning en voor minimaal zeven aaneengesloten nachten. Deze vergunningen lopen in 2019 af en worden niet meer opnieuw verstrekt. Daarmee komen er weer 800 woningen op de Amsterdamse woningmarkt beschikbaar, aldus Frank. Ook een tweede woning – waar je zelf dus niet staat ingeschreven als reguliere bewoner – mag je in Amsterdam niet verhuren aan toeristen.
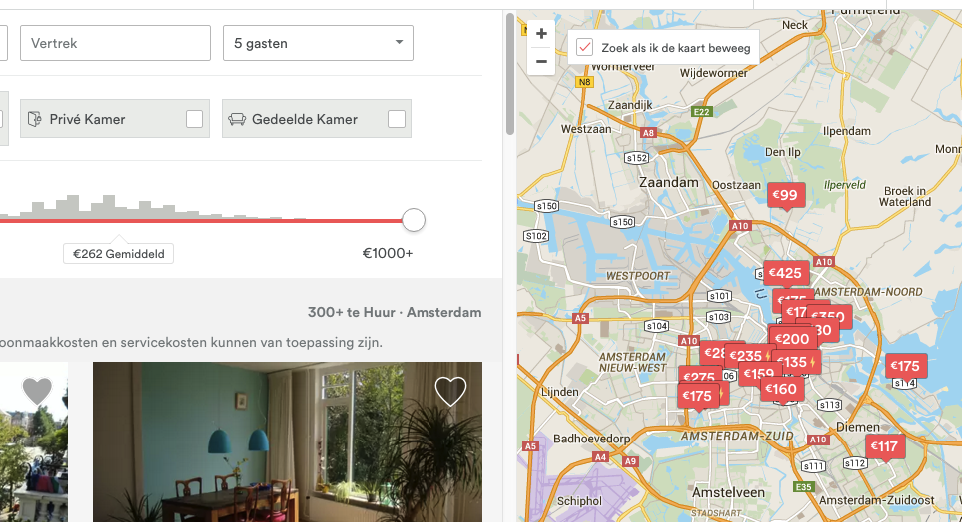 “Handhaving gebeurt veel en fors”, legde Frank verder uit. Zo richt Amsterdam zich via een meldpunt onder meer op klachten en meldingen over illegale vakantieverhuur, maar ook op sleutelbedrijven: volgens Frank overtreden die regelmatig de regels. Daarnaast wordt het web ‘gescraped’, waarbij patronen in verhuurgedrag worden onderzocht. Of hiermee voldoende wordt bereikt is de vraag: zoek zelf op locaties voor vijf, zes of zeven gasten (het kan tot en met 16+) en je vindt honderden aangeboden locaties in Amsterdam. De gemeente zegt alleen te kunnen handhaven op basis van ‘heterdaadjes’, maar er worden ook mystery guests ingezet.
“Handhaving gebeurt veel en fors”, legde Frank verder uit. Zo richt Amsterdam zich via een meldpunt onder meer op klachten en meldingen over illegale vakantieverhuur, maar ook op sleutelbedrijven: volgens Frank overtreden die regelmatig de regels. Daarnaast wordt het web ‘gescraped’, waarbij patronen in verhuurgedrag worden onderzocht. Of hiermee voldoende wordt bereikt is de vraag: zoek zelf op locaties voor vijf, zes of zeven gasten (het kan tot en met 16+) en je vindt honderden aangeboden locaties in Amsterdam. De gemeente zegt alleen te kunnen handhaven op basis van ‘heterdaadjes’, maar er worden ook mystery guests ingezet.
De boetes beginnen bij 12.000 euro (ook wanneer er verhuurd wordt aan meer dan vier personen) en kunnen meerder boetes opgelegd worden. Ook kunnen panden worden gesloten of huurcontracten worden opgezegd. De vakantieverhuur was in 2015 goed voor 834 klachten, er werden 167 hotels gesloten en er werd voor meer dan een miljoen euro aan boetes uitgedeeld.
Tot zo ver de ‘deel’-economie die Airbnb heet. Zelfregulering of een kleinere overheid? Nee, de gemeente moet juist hard aan het werk met beleid, handhaving en controle. De rankings op Airbnb hebben betrekking op de onderlinge beoordeling van huurders en verhuurders; met andere stakeholders houdt het businessmodel van Airbnb geen rekening. Innovatie en een beter milieu? Ik zie niet wat er innovatief is aan het online afspreken dat je bij een vreemde komt slapen. Het is gewoon hotelletje spelen, zonder dat je je aan kwaliteits- en veiligheidseisen hoeft te houden die we ooit allemaal samen bedacht hebben voor de horecasector. Met meer dan 800 gemelde klachten in een jaar levert Airbnb blijkbaar aardig wat overlast op. En hoewel transparantie helemaal van deze tijd is, is dat nu net iets waar Airbnb geen boodschap aan heeft: het bedrijf komt niet met volledige namen en adressen van locaties en verhuurders.
Er zijn honderden initiatieven die terecht of onterecht het predicaat deeleconomie meekrijgen. Ook innovatieve ondernemers weten dat ze met dat etiket snel op de sympathie van consumenten kunnen rekenen. De vindingrijkheid en het succes van deeleconomie-initiatieven houden niet altijd gelijke tred met kwaliteit en duurzaamheid. Bij Fiverr kan je voor het haast symbolisch bedrag van vijf dollar opdrachten uitzetten. Bijvoorbeeld het ontwerpen van een logo, of het vertalen van een paar honderd woorden. De bedragen staan vast, de omvang van de ‘gig’ varieert en wordt bepaald door de mensen die hun diensten aanbieden. Je moet wel opletten met wie je zaken doet. Als je een logo laat ontwerpen, kan het zo maar zijn dat het logo al bestaat – en dat je ontwerper voor vijf dollar vooral een kopieertrucje heeft gedaan. En als je terug wil naar de opdrachtnemer, moet je niet verbaasd zijn dat deze niet meer bestaat. Als er iets misgaat in de dienstverlening, en de opdrachtnemer is gevlogen, krijg je een tegoed voor een volgende keer. Ofwel: ook bij een wanprestatie ben je je geld kwijt. In het businessmodel van Fiverr is het nemen (of delen) van verantwoordelijkheid voor de bemiddelende rol niet inbegrepen. Delen is mooi, maar niet alles in de deeleconomie is wat het lijkt te zijn.








 Amsterdam ziet data ook als de sleutel tot het aanpakken van het vraagstuk van bijna
Amsterdam ziet data ook als de sleutel tot het aanpakken van het vraagstuk van bijna 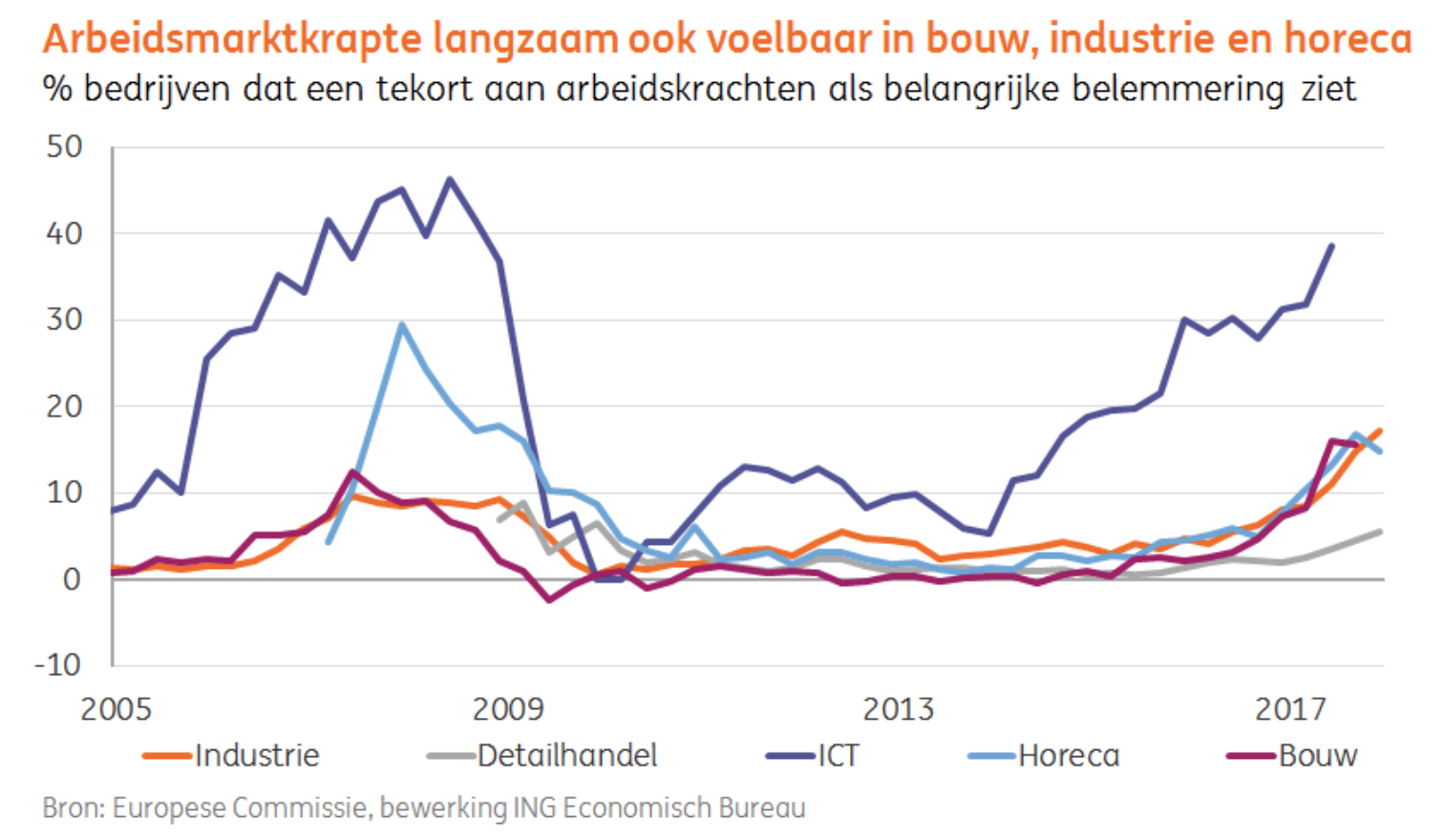
 De financiële sector moet data gaan delen en vrijwel gelijktijdig wordt de zeggenschap van burgers en consumenten over hun eigen data versterkt. Met de komst van twee complexe sets aan nieuwe Europese wetgeving – PSD-2 en GDPR – wordt de digitale samenleving er niet eenvoudiger op.
De financiële sector moet data gaan delen en vrijwel gelijktijdig wordt de zeggenschap van burgers en consumenten over hun eigen data versterkt. Met de komst van twee complexe sets aan nieuwe Europese wetgeving – PSD-2 en GDPR – wordt de digitale samenleving er niet eenvoudiger op.  Aan de ene kant krijgen consumenten (en daarmee – onder voorwaarden – bedrijven) zeggenschap over hun persoonlijke data, aan de andere kant worden de regels over het bezit en verwerken van data voor bedrijven enorm aangescherpt. Dit heeft grote gevolgen: bedrijven moeten in actie komen om alle nieuwe regelgeving door te voeren. Hun marketingorganisaties zullen zich moeten voorbereiden op nieuwe omstandigheden waarbij het bezit van klantdata niet meer vanzelfsprekend is. Ondernemingen zullen moeten accepteren dat ze te maken krijgen met payment service providers uit de fintech sector. Bedrijven worden gedwongen meer te communiceren met hun klanten over hoe ze met data omgaan en moeten er op anticiperen dat consumenten hun data zelfs gaan ‘terughalen’. Die consumenten zelf zullen in de nabije toekomst vaker beslissingen moeten nemen over hun persoonlijke data. Inmiddels is er een hele serie data-startups ontstaan, dat platforms aanbiedt om consumenten te helpen bij het managen (of zelfs vermarkten) van hun eigen data, zoals
Aan de ene kant krijgen consumenten (en daarmee – onder voorwaarden – bedrijven) zeggenschap over hun persoonlijke data, aan de andere kant worden de regels over het bezit en verwerken van data voor bedrijven enorm aangescherpt. Dit heeft grote gevolgen: bedrijven moeten in actie komen om alle nieuwe regelgeving door te voeren. Hun marketingorganisaties zullen zich moeten voorbereiden op nieuwe omstandigheden waarbij het bezit van klantdata niet meer vanzelfsprekend is. Ondernemingen zullen moeten accepteren dat ze te maken krijgen met payment service providers uit de fintech sector. Bedrijven worden gedwongen meer te communiceren met hun klanten over hoe ze met data omgaan en moeten er op anticiperen dat consumenten hun data zelfs gaan ‘terughalen’. Die consumenten zelf zullen in de nabije toekomst vaker beslissingen moeten nemen over hun persoonlijke data. Inmiddels is er een hele serie data-startups ontstaan, dat platforms aanbiedt om consumenten te helpen bij het managen (of zelfs vermarkten) van hun eigen data, zoals  Het was al een tijdje duidelijk dat data een belangrijk onderdeel van het bedrijfskapitaal vormen (ook al staan ze, net als intellectueel kapitaal, zelden op de balans). Organisaties zijn nog volop bezig met uitvinden hoe ze het
Het was al een tijdje duidelijk dat data een belangrijk onderdeel van het bedrijfskapitaal vormen (ook al staan ze, net als intellectueel kapitaal, zelden op de balans). Organisaties zijn nog volop bezig met uitvinden hoe ze het  De net iets meer dan een miljard gebruikers van Facebook leveren het bedrijf van Zuckerberg een
De net iets meer dan een miljard gebruikers van Facebook leveren het bedrijf van Zuckerberg een 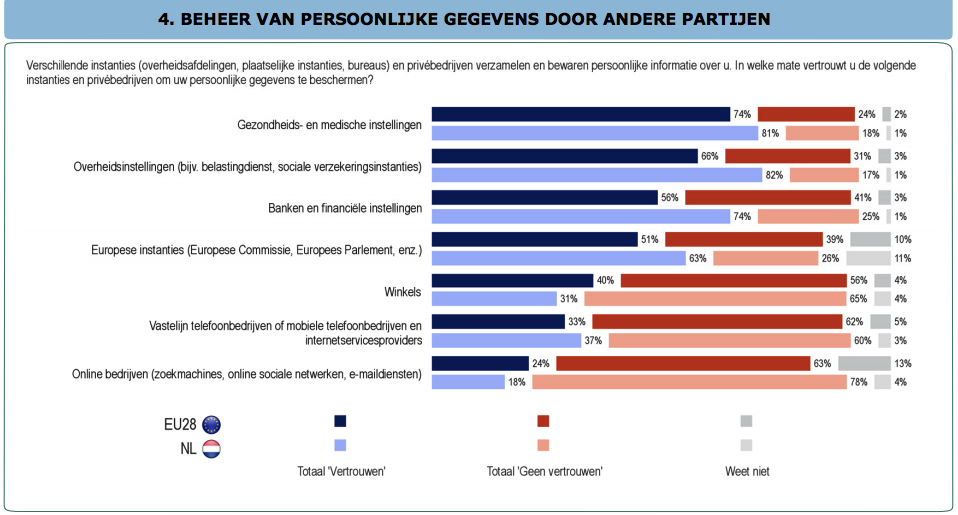
 Wanneer je vandaag de dag een nieuwe auto koopt, is het verstandig het koopcontract goed door te nemen. Niet alleen omdat daar is staat wat er onder de garantie valt, maar ook om te weten wat er bij de auto wordt geleverd. Je zult misschien geen reservewiel aantreffen, maar wel een heel pakket aan software – voor motormanagement, het monitoren van technische systemen en onderdelen en voor communicatie met de autofabrikant. Auto’s zijn computers op wielen. Ze worden geleverd met een IP-adres en een verzameling apps.
Wanneer je vandaag de dag een nieuwe auto koopt, is het verstandig het koopcontract goed door te nemen. Niet alleen omdat daar is staat wat er onder de garantie valt, maar ook om te weten wat er bij de auto wordt geleverd. Je zult misschien geen reservewiel aantreffen, maar wel een heel pakket aan software – voor motormanagement, het monitoren van technische systemen en onderdelen en voor communicatie met de autofabrikant. Auto’s zijn computers op wielen. Ze worden geleverd met een IP-adres en een verzameling apps.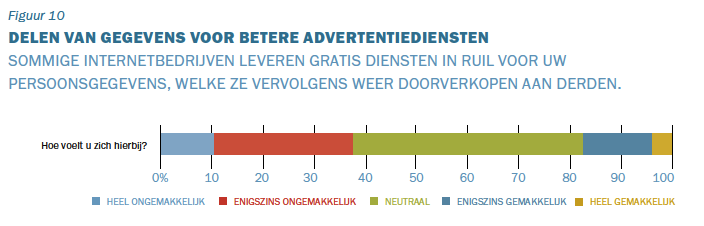
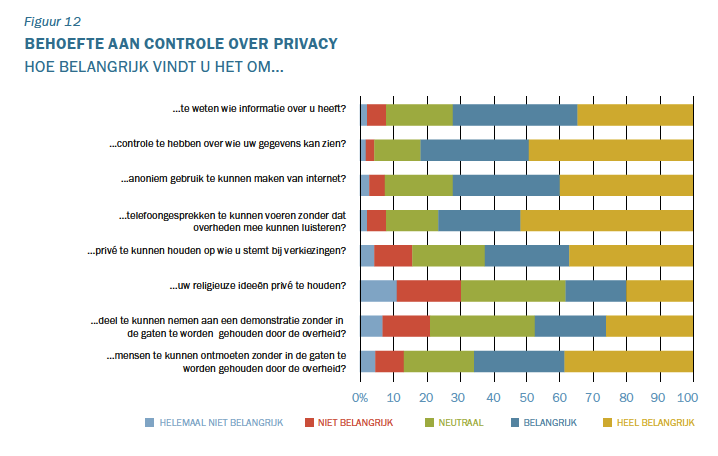

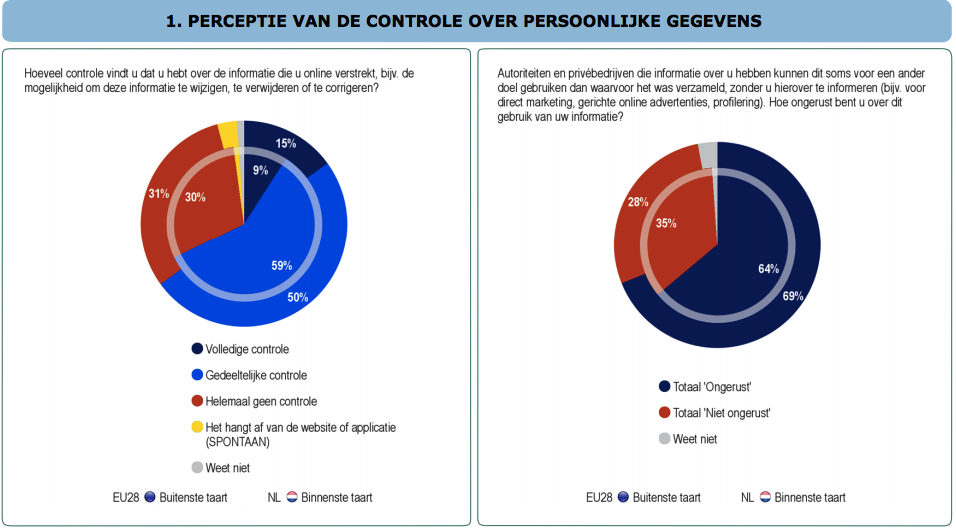
 Die onzichtbaarheid zorgt ook voor onverschilligheid, maar die wordt ook gevoed door de toenemende complexiteit. Voor een normaal mens is het al ingewikkeld om
Die onzichtbaarheid zorgt ook voor onverschilligheid, maar die wordt ook gevoed door de toenemende complexiteit. Voor een normaal mens is het al ingewikkeld om  geïntroduceerde verzekering ‘veilig rijden’ krijgt de verzekerde een ‘stick’ die op de
geïntroduceerde verzekering ‘veilig rijden’ krijgt de verzekerde een ‘stick’ die op de 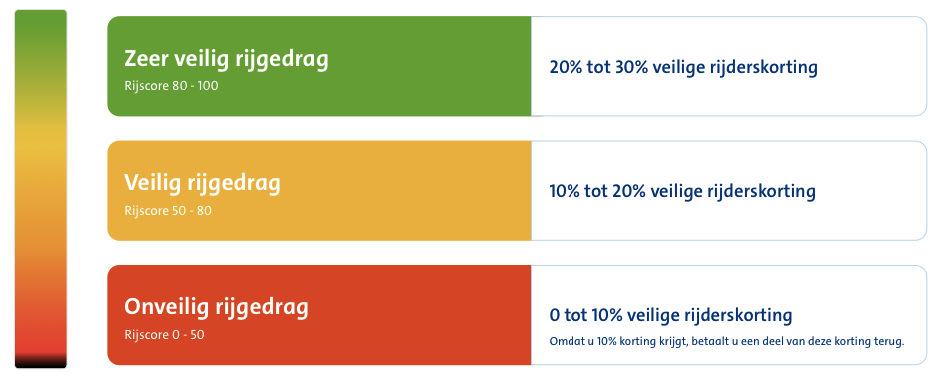 onderdelen: de rijsnelheid, de manier van optrekken en remmen en de wijze waarop bochten worden genomen. De rijstijl wordt herleidt tot een korting (of malus) op de premie; ook het tijdstip waarop je rijdt is mede bepalend voor de premiehoogte. Om gerichte feedback te kunnen geven op het onderdeel snelheid, moet de snelheidslimiet bekend zijn van de weg waarop de verzekerde rijdt. Daarom zit er ook een GPS-module in de dongel die de locatiegegevens levert. Daarnaast zal er ook een accelerometer in de dongel aanwezig moeten zijn – nodig om versnelling te kunnen waarnemen. Of met alle hardware en software veilig rijden kan worden gemonitord is de vraag; een noodstop maken voor een plotseling overstekend kind lijkt me noodzakelijk, maar veilig is het niet.
onderdelen: de rijsnelheid, de manier van optrekken en remmen en de wijze waarop bochten worden genomen. De rijstijl wordt herleidt tot een korting (of malus) op de premie; ook het tijdstip waarop je rijdt is mede bepalend voor de premiehoogte. Om gerichte feedback te kunnen geven op het onderdeel snelheid, moet de snelheidslimiet bekend zijn van de weg waarop de verzekerde rijdt. Daarom zit er ook een GPS-module in de dongel die de locatiegegevens levert. Daarnaast zal er ook een accelerometer in de dongel aanwezig moeten zijn – nodig om versnelling te kunnen waarnemen. Of met alle hardware en software veilig rijden kan worden gemonitord is de vraag; een noodstop maken voor een plotseling overstekend kind lijkt me noodzakelijk, maar veilig is het niet.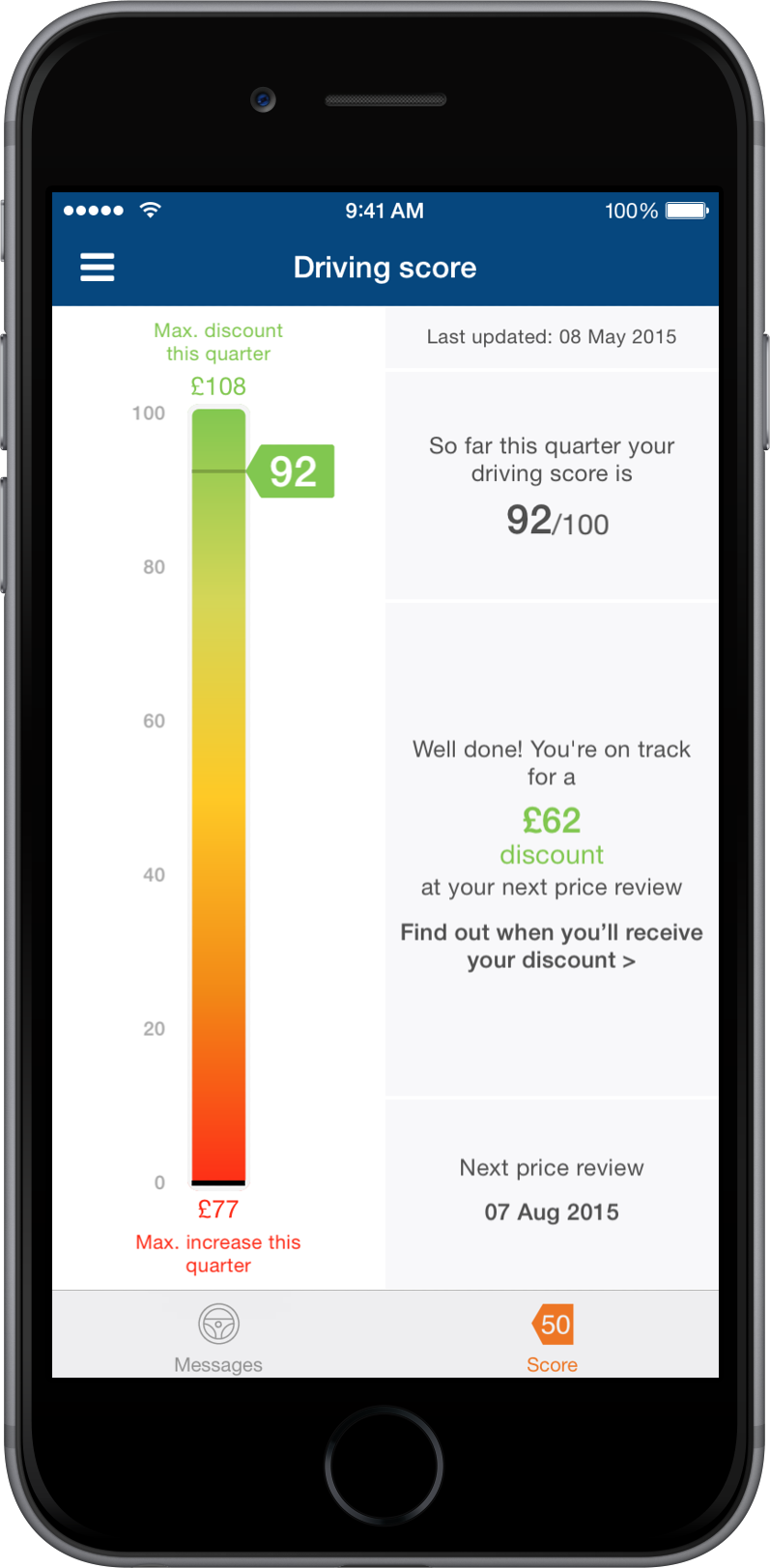 De connected car roept uiteraard privacy-vragen op, maar in het geval van de connected car ontstaat een nieuw probleem. Privacy is een individueel en persoonsgebonden fenomeen, zo benadrukt ook
De connected car roept uiteraard privacy-vragen op, maar in het geval van de connected car ontstaat een nieuw probleem. Privacy is een individueel en persoonsgebonden fenomeen, zo benadrukt ook