
 In de jaren 30 van de vorige eeuw kwam het Deutscher Musik Verband in verzet tegen de opkomst van de geluidsfilm. Die zou een aanslag op de kunst zijn, zorgen voor vervlakking en de ondergang betekenen voor de beroepsgroep van bioscoopmusici. ‘Als je niet begrijpt wat er speelt, begin je morgen een videotheek’ hoorde ik laatst.
In de jaren 30 van de vorige eeuw kwam het Deutscher Musik Verband in verzet tegen de opkomst van de geluidsfilm. Die zou een aanslag op de kunst zijn, zorgen voor vervlakking en de ondergang betekenen voor de beroepsgroep van bioscoopmusici. ‘Als je niet begrijpt wat er speelt, begin je morgen een videotheek’ hoorde ik laatst.
Sommige businessmodellen verdwijnen, eenvoudigweg omdat er iets nieuws komt dat het bestaande overbodig maakt. Sommige businessmodellen komen niet eens aan de beurt, omdat de onderliggende technologie niet doorbreekt – iets wat je kunt zien als je de Gartner Hype Cycle van 15 jaar geleden bekijkt. Tel de Wet van Moore en het netwerk effect bij elkaar op en je kunt niet anders concluderen dan dat de adaptieve organisatie er aan komt. Dat is een onderneming die zich richt op het produceren en leveren van gepersonaliseerde producten en diensten.
Trendwatchers, goeroes en futurologen houden vast aan twee basisprincipes van het moderne technologietijdperk: de Wet van Moore en het netwerkeffect. Kort samengevat: computers worden iedere twee jaar sneller en goedkoper, waardoor allerlei complexe taken gemakkelijker geautomatiseerd kunnen worden; het feit dat zo ongeveer alles online met elkaar is verbonden (het netwerkeffect) zorgt voor een enorme impact. Simpel gezegd: een fax is nutteloos, twee faxen vormen een minuscuul maar nuttig netwerkje, maar faxen op alle plekken van de wereld zorgen voor een haalbaar en schaalbaar toepassingsmodel. In de digitale wereld spreekt met in dit verband over exponentiële technologie.
Data als grondstof voor lerende systemen
De kern van een netwerk is het uitwisselen van data. Naast organisaties en individuen zijn straks ook machines en andere objecten massaproducenten van data. Door de sterk gegroeide rekencapaciteit van computers is data de grondstof geworden voor machine learning. Deze systemen kunnen patronen herleiden en herkennen uit grote hoeveelheden voorbeelden, uitspraken doen over de waarschijnlijkheid dat een inschatting correct is en leren van foute inschattingen. Als je een lerend systeem maar voldoende informatie geeft, kan het zelfs leren om mensen na te bootsen – een computer wordt niet empathisch, maar kan wel empathisch-lijkende responsen geven.
Lerende systemen vormen de basis voor een nieuwe generatie producten, diensten en complete organisaties volgens het Spotify-model. Of beter gezegd: voor ‘voorspellende’ en ‘adaptieve’ organisaties. Hoewel organisaties al decennia lang gebruik maken van data onder het mom van ‘meten is weten’, is het gebruik van data om actief en realtime te kunnen anticiperen relatief nieuw. Een goed voorbeeld van een organisatie die predictieve trekjes krijgt, is de moderne luchtvaartonderneming. Op basis van realtime informatie uit sensoren – een interne datastroom – weet het bedrijf welke onderdelen van een vliegtuig preventief onderhoud nodig hebben of moeten worden vervangen. Ook liftfabrikant KONE maakt op deze manier gebruik van data.
Onze data als basis voor onze voeding
Ook de consument is al in verregaande mate ‘connected’ en kan daarmee gezien worden als een onderdeel van het internet of things. Onze smartphone bevat ruwweg tien sensoren die informatie verschaffen over bijvoorbeeld beslissingen, persoonlijke eigenschappen en locatie. Voeg daar wearables en insidables (sensoren die op en in het lichaam kunnen worden aangebracht) aan toe en je hebt informatie over zowel gedrag als lichaamsfuncties. Die combinatie van lerende systemen en grote hoeveelheden data over ons gedrag en ons lichaam is het vertrekpunt van Jun Wang, een Chinese wetenschapper. Wang vertelde in juli 2015 aan Nature over zijn droom om adaptieve voeding te ontwikkelen. Zijn idee: het opzetten van een AI-systeem dat aangedreven wordt door informatie uit individuele DNA-profielen, gecombineerd met fysieke eigenschappen en informatie over leefpatroon. Wang is geen beginner op het gebied van DNA-sequencing: als CEO van het bedrijf BGI realiseerde hij dat het gnoom van de Reuzenpanda volledig in kaart werd gebracht.
Het doel van Wang is niet gering: mensen realtime informatie verschaffen over voeding en leefstijl die optimaal is afgestemd op hun situatie – die van moment tot moment verschilt. Ofwel: het systeem van Wang vertelt je ’s ochtends wat de status van je gezondheid is en wat je moet doen om er voor te zorgen dat je niet ziek wordt – over een dag, een week of een half jaar. Zijn plan gaat zo ver dat hij mensen toegang wil geven tot voeding op maat: dus precies die stoffen bevattend (van vitamines tot en met bacteriën) die je lijf gezond houden.
Leven om niet ziek te worden
Wat hij nodig heeft zijn systemen met grote rekenkracht, die algoritmes laten draaien die zoeken naar de relatie tussen genen, leefwijze en omgevingsfactoren. Die optelsom moet zijn kunstmatige intelligentie-oplossing in staat stellen te voorspellen hoe het menselijk lichaam uiteindelijk fysiek functioneert. Daarnaast wil hij de DNA-gegevens en gegevens over fysieke processen zoals stofwisseling, vetafbraak en eiwitopbouw van miljoenen individuen verzamelen. Door beide gegevenssets te combineren wil hij de relatie inzichtelijk maken tussen erfelijke eigenschappen en fysieke kenmerken. Hieruit wil hij onder meer volledig op het individu gerichte voedingsadviezen kunnen afleiden, die mensen proactief in staat stellen gezond(er) te leven en te anticiperen op aandoeningen. Naast een terabyte aan data per individu (dus een datacenter met voldoende rekenkracht) heeft hij ook 1,6 miljard dollar nodig.
Willen mensen van dag tot dag weten wat ze exact moeten doen (eten, bewegen) om niet ziek te worden? Wang is niet de enige die heil ziet in slimme voedingsadviezen: het is maar een klein stapje van ‘evidence based’ naar ‘datadriven’ gezondheidszorg en voedingsadvies. Een ding staat vast: als het project van Wang slaagt, staat een belangrijk deel van de economie – voedingsmiddelenindustrie, gezondheidszorg en van zorg- en levensverzekering – op zijn kop.
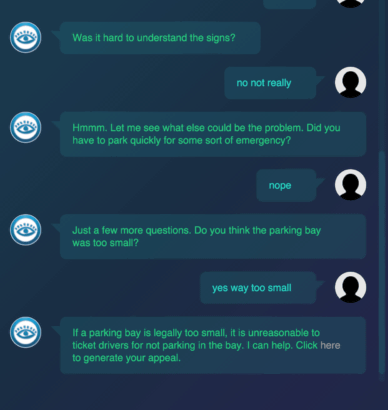
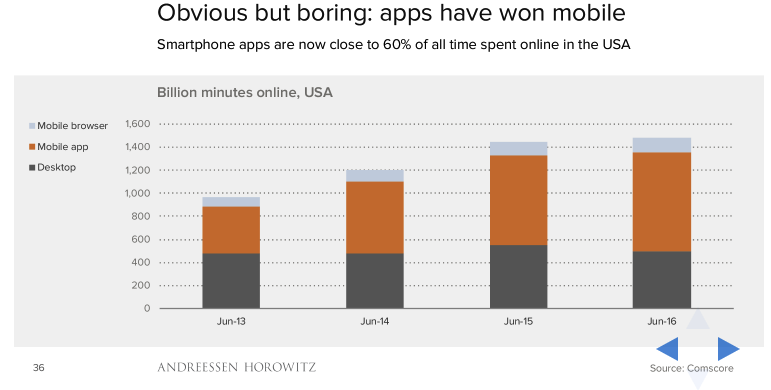
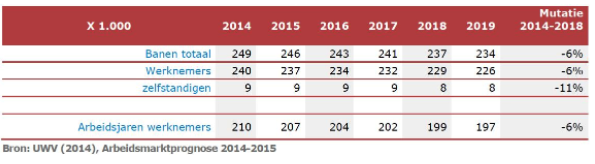
 Echte innovatie komt vaak neer op onverwachte, nieuwe combinaties uit onverwachte hoek. Wat zijn de ingrediënten voor totale disruptie in de consumentenmarkt? Nieuwe wet- en regelgeving voor banken, het internet of things en kunstmatige intelligentie. Uit dit mengsel komen oplossingen die precies aansluiten op wat consumenten willen: gemak, snelle en realtime dienstverlening, altijd online beschikbaar.
Echte innovatie komt vaak neer op onverwachte, nieuwe combinaties uit onverwachte hoek. Wat zijn de ingrediënten voor totale disruptie in de consumentenmarkt? Nieuwe wet- en regelgeving voor banken, het internet of things en kunstmatige intelligentie. Uit dit mengsel komen oplossingen die precies aansluiten op wat consumenten willen: gemak, snelle en realtime dienstverlening, altijd online beschikbaar.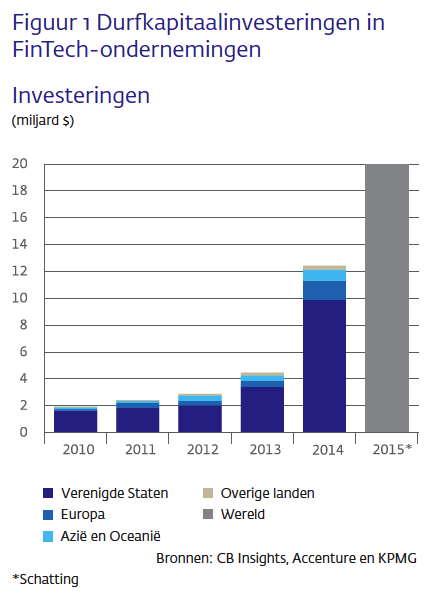 De investeringen in fintech-bedrijven zijn de laatste jaren enorm toegenomen. Dat vergroot de kans op een enorme shake out, maar ook op succesvolle initiatieven die de bancaire dienstverlening sterk zullen veranderen. De beste kansen zijn er voor diensten die ‘ten times better’ zijn dan bestaande diensten. Het geheim van dat succes ligt soms in een detail; soms komt het neer op het maken van slimme, nieuwe combinaties. Bijvoorbeeld door je rekeningen van verschillende financiële instellingen (bank, creditcardmaatschappij, beleggingen), te combineren in één omgeving. Of door budget- of boekhoudsoftware te integreren in je bankomgeving. Of door betaaltransacties ‘onzichtbaar’ te maken, iets waar (online) retail wel oren naar heeft. Shopping cart abandonment is een groot probleem: omslachtige betaalprocedures met pasjes, codes en identifiers zorgen voor 45 procent afhakers bij het online aankoopproces. Er liggen dus enorme kansen als je de kloof tussen ‘aanbod’ en ‘betaling’ weet te verkleinen.
De investeringen in fintech-bedrijven zijn de laatste jaren enorm toegenomen. Dat vergroot de kans op een enorme shake out, maar ook op succesvolle initiatieven die de bancaire dienstverlening sterk zullen veranderen. De beste kansen zijn er voor diensten die ‘ten times better’ zijn dan bestaande diensten. Het geheim van dat succes ligt soms in een detail; soms komt het neer op het maken van slimme, nieuwe combinaties. Bijvoorbeeld door je rekeningen van verschillende financiële instellingen (bank, creditcardmaatschappij, beleggingen), te combineren in één omgeving. Of door budget- of boekhoudsoftware te integreren in je bankomgeving. Of door betaaltransacties ‘onzichtbaar’ te maken, iets waar (online) retail wel oren naar heeft. Shopping cart abandonment is een groot probleem: omslachtige betaalprocedures met pasjes, codes en identifiers zorgen voor 45 procent afhakers bij het online aankoopproces. Er liggen dus enorme kansen als je de kloof tussen ‘aanbod’ en ‘betaling’ weet te verkleinen. 

 De komende tijd zal customer service steeds vaker te maken krijgen met data van connected apparaten – denk aan de
De komende tijd zal customer service steeds vaker te maken krijgen met data van connected apparaten – denk aan de 
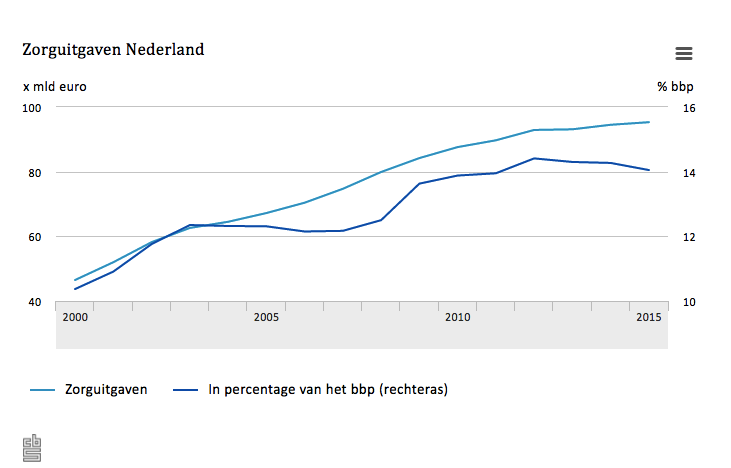 Het betaalbaar houden van ons zorgstelsel is een grote uitdaging. De
Het betaalbaar houden van ons zorgstelsel is een grote uitdaging. De  De patiënt verandert
De patiënt verandert
 Het
Het 

 Ook autoverhuurder Herz wordt opgevoerd als een big data succesverhaal. Het bedrijf is actief in 140 landen en zit op een berg aan data van e-mails, tekstberichten en online vragenlijsten. Met die data zou Hertz beter in staat zijn te weten wat de klanten willen en beweert het bedrijf bovendien de relatie tussen manager en klant te kunnen verbeteren. De resultaten die Hertz boekte, waren
Ook autoverhuurder Herz wordt opgevoerd als een big data succesverhaal. Het bedrijf is actief in 140 landen en zit op een berg aan data van e-mails, tekstberichten en online vragenlijsten. Met die data zou Hertz beter in staat zijn te weten wat de klanten willen en beweert het bedrijf bovendien de relatie tussen manager en klant te kunnen verbeteren. De resultaten die Hertz boekte, waren  Een derde van de Nederlanders heeft in 2015 wel eens
Een derde van de Nederlanders heeft in 2015 wel eens  Cloudrun
Cloudrun De net iets meer dan een miljard gebruikers van Facebook leveren het bedrijf van Zuckerberg een
De net iets meer dan een miljard gebruikers van Facebook leveren het bedrijf van Zuckerberg een 
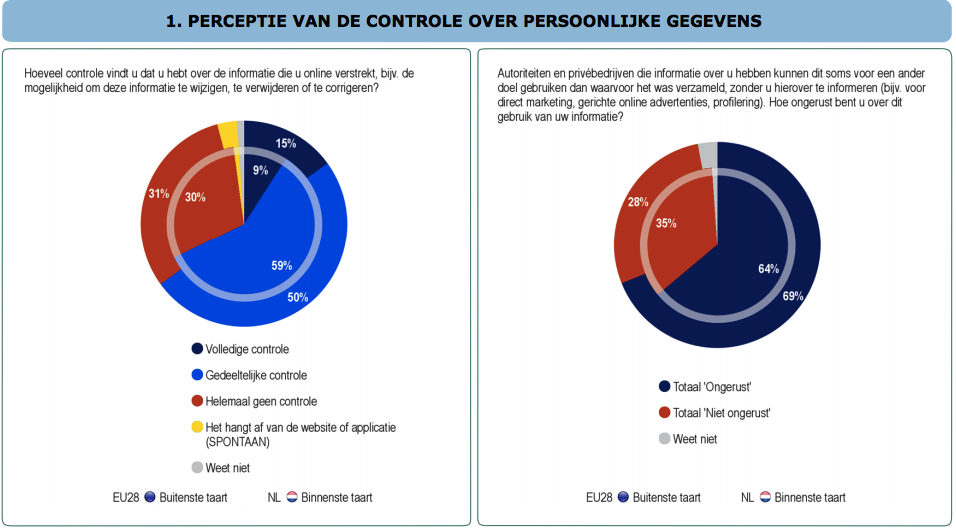
 Wanneer je vandaag de dag een nieuwe auto koopt, is het verstandig het koopcontract goed door te nemen. Niet alleen omdat daar is staat wat er onder de garantie valt, maar ook om te weten wat er bij de auto wordt geleverd. Je zult misschien geen reservewiel aantreffen, maar wel een heel pakket aan software – voor motormanagement, het monitoren van technische systemen en onderdelen en voor communicatie met de autofabrikant. Auto’s zijn computers op wielen. Ze worden geleverd met een IP-adres en een verzameling apps.
Wanneer je vandaag de dag een nieuwe auto koopt, is het verstandig het koopcontract goed door te nemen. Niet alleen omdat daar is staat wat er onder de garantie valt, maar ook om te weten wat er bij de auto wordt geleverd. Je zult misschien geen reservewiel aantreffen, maar wel een heel pakket aan software – voor motormanagement, het monitoren van technische systemen en onderdelen en voor communicatie met de autofabrikant. Auto’s zijn computers op wielen. Ze worden geleverd met een IP-adres en een verzameling apps.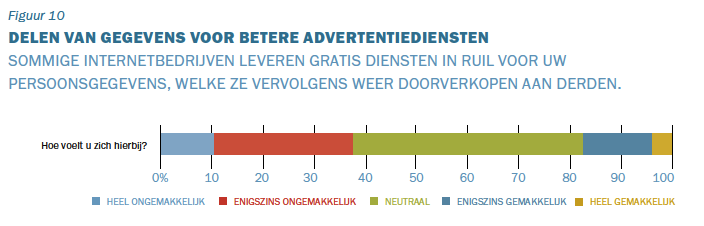
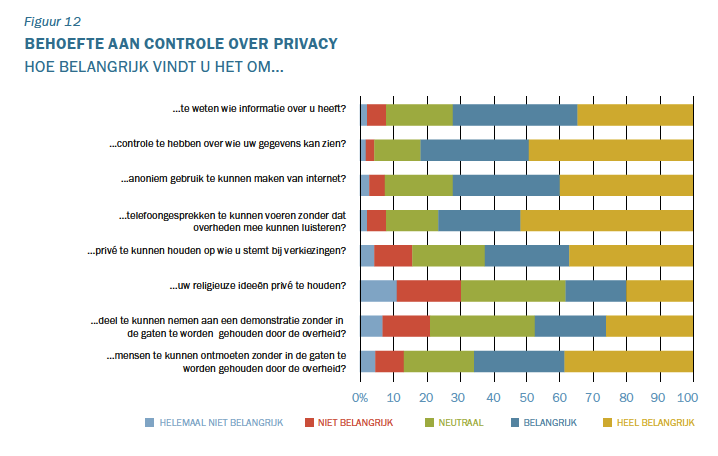

 Die onzichtbaarheid zorgt ook voor onverschilligheid, maar die wordt ook gevoed door de toenemende complexiteit. Voor een normaal mens is het al ingewikkeld om
Die onzichtbaarheid zorgt ook voor onverschilligheid, maar die wordt ook gevoed door de toenemende complexiteit. Voor een normaal mens is het al ingewikkeld om