Ieder jaar organiseert de Klantenservice Federatie, de branchevereniging voor bedrijven die zich bezighouden met klantcontact en e-commerce, haar jaarcongres. Silovorming en denken in profielen, kanalen, segmenten en andere hokjes staat een soepele dienstverlening aan klanten vaak in de weg. Aegon liet zien hoe een onderbouwde customer experience strategie een eind kan maken aan de nutteloze discussie over kosten en baten van klantcontact. En: de snelle ontwikkeling van spraakplatformen zoals Google Assistant heeft mogelijk ingrijpende gevolgen voor het contactcenter. Is het straks de Google Assistant die bepaalt of klanten nog in jouw contactcenter binnenkomen?
Kom op een congres of seminar dat een raakvlak heeft met klantcontact en KIRC staat op het podium. Dat podium wordt dan op drie manieren gebruikt: het promoten van KIRC als kenniscentrum (wat weer een marketingvehikel is van een rijtje dienstverleners), het verzamelen van kengetallen en het presenteren van trends. Meestal stort KIRC in sneltreinvaart een reeks aan cijfers, grafieken en tabellen uit over het publiek.
De gegevens die KIRC presenteert, zijn afkomstig uit eigen onderzoek, maar ook uit onderzoek van derden zoals KCM, Genesys, Dimension Data, Verint en Teleperformance. Door de veelheid aan (verschillende soorten) informatie is het uiteindelijk lastig de hoofdtrends te onderscheiden. Zo worden meningen en opvattingen over trends en patronen afgewisseld met kwantitatieve inschattingen van respondenten over volumes, behaalde doelstellingen en klantfeedback. Soms zijn cijfers wel te vergelijken met voorgaande jaren, soms niet. En soms wordt in vragen een combinatie van containerbegrippen gepresenteerd: ‘is customer experience verankerd in het DNA van de organisatie?’ Die vraag is extra ingewikkeld omdat het contactcenter zelden nog de enige partij is die de customer experience of customer journey bepaalt of beïnvloedt: de rol van ketenpartners wordt steeds belangrijker. Denk aan e-commerce waar de kwaliteit van logistieke dienstverleners en wederverkopers een stempel op de totale beleving drukt.
Direct contact versus selfservice
Gelukkig heeft KIRC alle cijfers in een boekje gebundeld, waarbij Geeske te Gussinklo de hoofdlijnen kort samenvat; daarnaast is er een goede management summary. Direct contact (in plaats van selfservice) scoort nog altijd het hoogst – komt dat door een absolute voorkeur bij consumenten of de hoogste doeltreffendheid? Selfservice is en blijft een zorgenkindje: ruwweg vier van de tien interacties verloopt niet goed. Ook chatbots presteren nog ondermaats: ook hier is de succesratio net geen 60%. De doorlopende zoektocht naar manieren om meer met data te doen leidt tot meer applicaties en dus wordt systeemintegratie een een ander zorgpunt. Een andere belangrijke constatering kwam van SAMR. Uit onderzoek uitgevoerd in samenwerking met de Rijksuniversiteit Groningen blijkt dat bedrijven baat kunnen hebben bij scherp afgebakende doelstellingen op het vlak van klanttevredenheid. De grootste meeropbrengst in termen van retentie en herhaalaankopen kan gerealiseerd worden als bedrijven hun klanttevredenheid van een zeven naar een acht weten te brengen. Maar hogere ‘rapportcijfers’ leveren nauwelijks iets op. Of dat aan de terughoudendheid van Nederlanders om een hoger cijfer te geven of dat ‘goede dienstverlening’ net wordt zo gewaardeerd als ‘excellente’ dienstverlening, werd niet toegelicht.
Digitalisering van klantcontact
Digitalisering leidt tot minder live contact. Althans, dat is de opzet, de grootste krimp in contactcenters lijkt gerealiseerd te zijn met de opkomst van selfservice. Maar volgens de cijfers worden klanten daar niet echt blijer van. Geen enkele consument heeft ‘bellen met bedrijf A, B of C als hobby. Daarnaast kan op dit moment nog niet worden gezegd dat invoering van de chatbot banen kost. Het gebruik van chat en whatsapp neemt toe, maar de volumes aan e-mail en telefoontjes nemen niet echt af.
Beide onderwerpen kwamen terug in twee andere bijdragen tijdens het KSF-congres. Aegon liet zien hoe The Experience Economy van Joe Pine het bedrijf hielp bij het verbeteren van de servicestrategie. En een presentatie van Google zou alle klantcontactprofessionals moeten wakker schudden. Het is niet je eigen chatbot die voor een verandering gaat zorgen, het wordt een van de drie technologiereuzen die de eerstelijns customer service van je gaat afpakken (of overnemen).
Cost center of value center?
 In de wereld van klantcontact speelt de discussie over kosten en opbrengsten van het contactcenter al jaren. Is het contactcenter een costcenter of een value center? Nu kost een afdeling bestaand uit assets en resources per definitie geld, dus in veel bedrijven begint het contactcenter al op achterstand. Rien Brus, Global VP of Customer Strategy bij verzekeraar Aegon heeft zijn organisatie geholpen om scherpere keuzes te maken: allereerst van productgericht naar klantgericht denken en daarna van kosten naar waarde. Impliciet gaat daarachter een afwijkend paradigma schuil: omzet en winst zijn geen doel op zich, maar een resultaat van het hebben van klanten (die blijkbaar bereid zijn om bij jou diensten of producten in te kopen).
In de wereld van klantcontact speelt de discussie over kosten en opbrengsten van het contactcenter al jaren. Is het contactcenter een costcenter of een value center? Nu kost een afdeling bestaand uit assets en resources per definitie geld, dus in veel bedrijven begint het contactcenter al op achterstand. Rien Brus, Global VP of Customer Strategy bij verzekeraar Aegon heeft zijn organisatie geholpen om scherpere keuzes te maken: allereerst van productgericht naar klantgericht denken en daarna van kosten naar waarde. Impliciet gaat daarachter een afwijkend paradigma schuil: omzet en winst zijn geen doel op zich, maar een resultaat van het hebben van klanten (die blijkbaar bereid zijn om bij jou diensten of producten in te kopen).
Brus haalt daarbij Joseph Pine aan, auteur van The Experience Economy, over hoe economische waardecreatie zich ontwikkelt. Pierre Spaninks geeft daarvan een bondige samenvatting: “In de grondstoffeneconomie werd er nog gewoon geld verdiend aan meel en eieren. In de productie-economie aan de taarten die je daarmee kon bakken. In de diensteneconomie aan het bezorgen van die taarten. En in de beleveniseconomie aan workshops waar culi’s zich even een heuse banketbakker konden wanen. De volgende fase voorspelden Pine en Gilmore ook alvast: de transformatie-economie. Dan betalen mensen goud geld om te leren hoe ze weer van die taarten af kunnen blijven.”
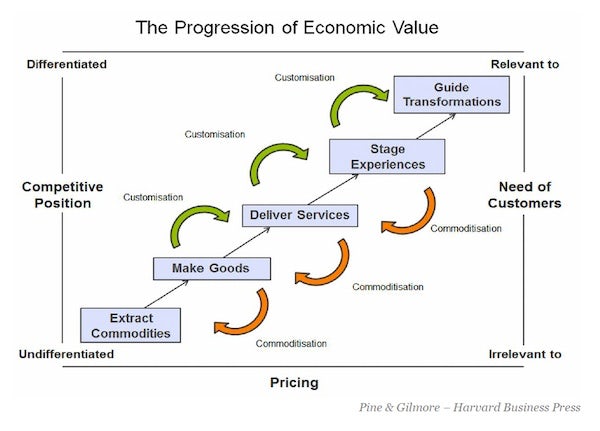
Klantcontact is een activiteit die zich afspeelt op het niveau van service en experience. Wat Brus betreft is het gemakkelijk om te zien wat het verschil is tussen commodities en producten, maar hoe kan klantcontact nu waarde toevoegen? Gaat het om noodzakelijke transacties (eenvoudigweg omdat het product of de dienst nu eenmaal tot vragen leidt: service als bijproduct van het product zelf) of om iets ‘hogers’ dat bijdraagt aan omzet en winst? Het antwoord op die vraag is belangrijk om te weten waar je wel en niet in moet investeren: kostenminimalisatie of opbrengsten-optimalisatie.
Volgens Brus ligt het antwoord besloten in het fenomeen ‘tijd’. Tijd is schaars, niet alleen voor mensen die in bedrijven werken, maar ook voor consumenten. Ze kunnen kiezen waar ze die tijd het liefst aan besteden en ook het besparen van tijd (door snelheid en gemak) kunnen aantrekkelijk zijn voor klanten. Het leveren van commodities, producten en services is gericht op het bieden van gemak en het besparen van tijd (‘time well saved’). Zodra je van ‘services’ naar ‘experiences’ en ‘transformations’ gaat, draait het voor consumenten om iets anders, namelijk ‘time well spent’.
‘Time well spent’ in een contactcenter?
In contactcenters bestaat de neiging verwachtingen van klanten ‘te overtreffen’ met ‘excellente service’. Maar is ‘time well spent’ haalbaar als klantcontact is ingericht op doelstellingen die te maken hebben met snel, eenvoudig en gemakkelijk – door managers vaak vertaald in standaardisatie en automatisering? Je kunt pas spreken van ‘time well spent’ als een interactie blijft hangen in de herinnering van een klant, als de interactie relevant en persoonlijk is. Hoe zwaarder deze eigenschappen aanwezig zijn, hoe meer ze bijdragen aan tevredenheid, retentie en uiteindelijk omzet, aldus Brus. Contacten die het minst bijdragen, moet je elimineren (of reduceren).
Design thinking?
Het model van Pine bestaat al sinds eind jaren negentig, maar biedt nog steeds concrete houvast bij de vraag hoe bedrijven afwegingen kunnen maken bij investeringsbeslissingen in klantcontact. De kunst is daarbij om niet zelf te bepalen wat waarde toevoegt of slechts ‘tijd bespaart’, maar de klant dit te laten doen. Het betrekken van de klant in het ontwerpen van dienstverlening kwam echter niet naar voren: niet bij Aegon, niet bij een andere presentatie van zorgverzekeraar CZ en evenmin bij het KSF Jaarcongres als geheel. Ofwel: klantcontactexperts praten liever over de klant dan met de klant. Dat is vreemd, want de klantcontactsector is nu juist op zoek naar wat bepalend is voor ‘relevantie’. Het is nog vreemder als je ziet dat de sector op basis van cijfers weet hoe klanten bepaalde oplossingen (zoals de eerste generatie chatbots waar veel bedrijven nu in investeren) waarderen.
Google wil ons naar ‘the age of assistance’ brengen
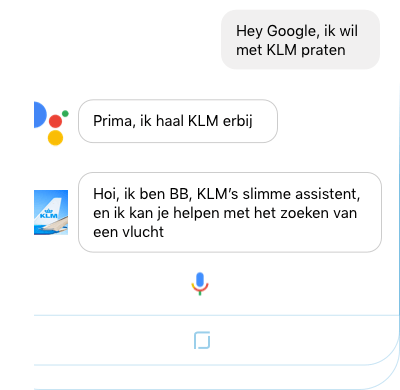
Dan naar Google. Karlijn Pels en Petra Stojanovic lieten zien hoe personalisatie (bijvoorbeeld op basis van persoonlijke gegevens en locatie) doordringt in het gebruik van Google. Consumenten zoeken steeds vaker met aanvullende vragen zoals ‘beste’, ‘in de buurt’ en ‘op dezelfde dag bezorgd’. Wat Google betreft zijn we de afgelopen tien jaar bezig geweest met mobile first en breekt nu een tijdperk aan: de ‘age of assistance’. Pels en Stojanovic wijzen er op dat veel klantvragen – voordat ze bij de website met selfservice of een contactcenter van een bedrijf uitkomen – beginnen met een zoekvraag bij een zoekmachine.
 Google laat zien hoe bol.com, KLM, Albert Heijn, PostNL en zelfs Andrelon al zijn aangehaakt op het spraakplatform van Google. Het Unilever-shampoomerk werkt daarbij samen met Kruidvat en omvat ook een besteloptie. De boodschap van Google is duidelijk: haak nu aan, want dan kan je leren van hoe de consument met deze nieuwe technologie omgaat. Om die boodschap kracht bij te zetten gaf developer Lee Boonstra een live demo hoe je eenvoudig met een drag-and-drop-achtige aanpak een chatbotdialoog kunt inrichten. Nodig: data als trainingsmateriaal (denk aan voorbeeldzinnen), Actions on Google en het dialogenbouwpakket Dialog, beiden uit de stal van Google. De reacties van de gebruiker tijdens de dialoog worden niet alleen gebruikt om de dialoog te sturen; met behulp van sentiment monitoring wordt gekeken welke onderdelen van de dialoog tot (on)tevredenheid of broodnodige escalatie leiden.
Google laat zien hoe bol.com, KLM, Albert Heijn, PostNL en zelfs Andrelon al zijn aangehaakt op het spraakplatform van Google. Het Unilever-shampoomerk werkt daarbij samen met Kruidvat en omvat ook een besteloptie. De boodschap van Google is duidelijk: haak nu aan, want dan kan je leren van hoe de consument met deze nieuwe technologie omgaat. Om die boodschap kracht bij te zetten gaf developer Lee Boonstra een live demo hoe je eenvoudig met een drag-and-drop-achtige aanpak een chatbotdialoog kunt inrichten. Nodig: data als trainingsmateriaal (denk aan voorbeeldzinnen), Actions on Google en het dialogenbouwpakket Dialog, beiden uit de stal van Google. De reacties van de gebruiker tijdens de dialoog worden niet alleen gebruikt om de dialoog te sturen; met behulp van sentiment monitoring wordt gekeken welke onderdelen van de dialoog tot (on)tevredenheid of broodnodige escalatie leiden.
Heeft Google straks als eerste contact met jouw klant?
Machine learning zorgt ervoor dat er momenteel in hoog tempo enorme stappen worden gemaakt in geautomatiseerde dialogen – “We zijn nog maar een paar maanden bezig”, aldus Google.
Het is de vraag of contactcentermanagers en marketeers al door hebben dat een spraakplatform dé manier is om consumentenvragen die buiten de organisatie bestaan, naar binnen te halen. Google en Amazon zijn beiden op hun eigen manier al diep doorgedrongen in e-commerce. Nu beide bedrijven ook een spraakplatform hebben opgetuigd, ligt het binnen handbereik dat zij ook de eerstelijns customer service geautomatiseerd gaan verzorgen: transacties, eenvoudige interacties, standaardvragen. Dan krijgt het ‘wegautomatiseren’ van eenvoudige klantvragen plotseling een heel andere betekenis: is het straks de Google Assistant die bepaalt of klanten wel of niet worden doorverbonden met jouw organisatie?