
De cloud wordt het ideale platform voor het internet of things (IoT). De cloud is snel op te tuigen en in te richten, is op afstand toegankelijk, maar locatieonafhankelijk, kan enorm snel worden opgeschaald en kost relatief weinig geld. Het vormt ook de ideale basis voor een wireless sensor netwerk (WNS): een netwerk van sensoren, die door hun lage energieverbruik autonoom functioneren en in staat zijn permanent data door te geven aan het web. Denk aan sensoren in onze directie omgeving: systemen voor het bepalen van de luchtkwaliteit, sensoren die het klimaat in gebouwen optimaal reguleren.
Ook sensoren die we nu al intensief gebruiken – bijvoorbeeld bewakingscamera’s in en om gebouwen – zullen, voor zo ver ze dat niet al doen, steeds vaker hun data in de cloud opslaan. De schaalbaarheid (niet alleen voor opslag, maar ook voor analysecapaciteit) en de gemakkelijk te organiseren toegankelijkheid maken de cloud de ideale thuisbasis voor de sensordata die het IoT in toenemende mate gaat produceren.
Het idee achter een meer en meer connected world is dat onze mogelijkheden toenemen: we krijgen meer informatie over en meer vat op de systemen om ons heen. Daardoor kunnen we processen efficiënter inrichten, verspilling tegen gaan, bij complexe vraagstukken sneller tot conclusies komen en bepaalde verschijnselen eerder ontdekken, zo luidt de belofte. Kortom, (big) data gaan ons leven prettiger maken.
Maar het produceren van meer – of liever gezegd, meer nieuwe informatie, maakt ons ook kwetsbaarder. Denk aan een connected auto die gehackt kan worden, of inbrekers die aan de hand van domotica-gegevens precies weten wanneer ze moeten inbreken.
Wanneer onze zorg en aandacht rondom security vooral uitgaat naar de klassieke criminelen die met hacks onze systemen willen gijzelen, dan maken we een grote denkfout. Het vertrouwen in cloudtechnologie loopt de meest ernstige schade op, als niet criminelen, maar onze eigen medemensen – overheidsdienaren, civil servants die we zelf hebben aangewezen – misbruik van hun informatieprivileges gaan maken, ook al beloven ze dat ze de burger zullen beschermen tegen een overheid met expansiedrift.
De afgelopen zomer heeft cloudcomputing al de eerste ernstige deuken opgelopen en niet doordat commerciële spelers te snel gewaagde diensten en producten lanceerden. In de VS waren het de NSA-praktijken die het cloudconcept onder enorme druk zetten. Zo onthulde de Britse krant The Guardian dat de NSA via geheime gerechtelijke dwangbevelen de mogelijkheid gebruikte om clouddata af te tappen van miljoenen Verizon-klanten. Voor het eerste werd duidelijk in de VS wat de kracht was van de Patriot Act. Het ging niet langer om een ‘mogelijkheid’ dat jouw persoonlijke data door de overheid zouden kunnen worden opgevraagd, maar om de realiteit dat ze al waren gekopieerd en opgeslagen door die overheid. Weg privacy.
Bij het uitrollen van nieuwe IoT-modellen en -concepten (bijvoorbeeld protocollen voor machine-to-machine-communicatie zoals bij slimme energiemeters of on demand diensten voor gebouwenbewaking) houden ontwikkelaars nadrukkelijk rekening met security-aspecten van zowel M2M als cloud. Wanneer systemen onbetrouwbaar blijken te zijn, zullen consumenten ze massaal de rug toe keren, hetgeen dergelijke concepten financieel kwetsbaar maakt. Er is bij datagebaseerde diensten geen tweede kans zoals bij fysieke producten waarbij je met een goede recall actie de schade nog kunt proberen te beperken. In het een betrouwbaar Internet of Things wordt authenticiteit van dingen een belangrijk element. Is de sensor wel het apparaat dat het beweert te zijn? Hoe kan voorkomen worden dat Things ongeoorloofd elkaars identiteit overnemen? Daarnaast speelt data-integriteit een belangrijke rol: is de informatie die een sensor afstaat, nog steeds dezelfde informatie die uiteindelijk op een tussen- of eindbestemming wordt opgeslagen?
Wat is de waarde van dit soort inspanningen? De belangrijkste voorwaarde om met een prettig gevoel het cloud tijdperk te betreden, blijft toch een betrouwbare overheid. Wanneer die het keer op keer laat afweten, worden alle andere maatregelen op het gebied van security – ook die van de overheid zelf, bijvoorbeeld om ons op te voeden op het vlak van datasecurity – een lachertje. In plaats van meer veiligheid en betrouwbaarheid is het eindresultaat het omgekeerde: de stap naar cybermuiterij, cyberterrorisme en cyberactivisme wordt steeds kleiner, zoals Edward Snowden al overtuigend heeft laten zien. En last but not least wordt het gedrag van overheden een ernstig obstakel voor innovatie.
Deze post is tot stand gekomen in samenwerking met de Zero Distance community en T-Systems
[wp_twitter]

 pas teruglopen wanneer de jongste generatie klanten de overhand heeft. Die jongste generatie wil alles online kunnen oplossen en regelen; als er een vraag rijst, moet een facebook- of whatsapp-berichtje voldoende zijn om de klantenservice in beweging te krijgen.
pas teruglopen wanneer de jongste generatie klanten de overhand heeft. Die jongste generatie wil alles online kunnen oplossen en regelen; als er een vraag rijst, moet een facebook- of whatsapp-berichtje voldoende zijn om de klantenservice in beweging te krijgen. service levels en responstijden. Snelheid voor de nieuwe consument is echter het aantal clicks waarmee je bij de juiste informatie komt, een bestelling kunt plaatsen of een vraag kunt stellen. Snelheid is ook het tempo waarmee geleverd wordt: real time zoals bij apps voor online bankieren en binnen een half uur als het gaat om fysieke distributie. Waarom is het wel mogelijk dat er binnen een half uur een pizza bij mij wordt afgeleverd, maar niet mijn favoriete boek, smartphone-accessoire of cadeautje?
service levels en responstijden. Snelheid voor de nieuwe consument is echter het aantal clicks waarmee je bij de juiste informatie komt, een bestelling kunt plaatsen of een vraag kunt stellen. Snelheid is ook het tempo waarmee geleverd wordt: real time zoals bij apps voor online bankieren en binnen een half uur als het gaat om fysieke distributie. Waarom is het wel mogelijk dat er binnen een half uur een pizza bij mij wordt afgeleverd, maar niet mijn favoriete boek, smartphone-accessoire of cadeautje?
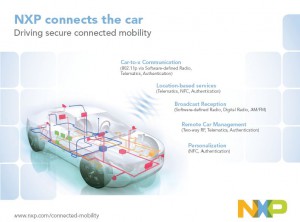 volledige garantie wanneer je de data die je auto genereert ter beschikking stelt aan derden – het automerk of de dealer. Die data werden normaal gesproken al uitgelezen tijdens onderhoudsbeurten, maar nu gaat dat 24/7 en real time. Die voorwaarde lijkt een nieuwe beperking van je privacy, maar op dat moment sta je er niet bij stil dat je gangen al gevolgd worden door camera’s boven snelweg en in de stad; en dat bij trajectcontroles naast je snelheid ook je identiteit, positie en tijd worden vastgelegd. Zonder dat je het weet, sta je tijdens je rit overigens al locatiegegevens af via je smartphone – rechtstreeks en via apps die daarvoor je toestemming hebben gekregen.
volledige garantie wanneer je de data die je auto genereert ter beschikking stelt aan derden – het automerk of de dealer. Die data werden normaal gesproken al uitgelezen tijdens onderhoudsbeurten, maar nu gaat dat 24/7 en real time. Die voorwaarde lijkt een nieuwe beperking van je privacy, maar op dat moment sta je er niet bij stil dat je gangen al gevolgd worden door camera’s boven snelweg en in de stad; en dat bij trajectcontroles naast je snelheid ook je identiteit, positie en tijd worden vastgelegd. Zonder dat je het weet, sta je tijdens je rit overigens al locatiegegevens af via je smartphone – rechtstreeks en via apps die daarvoor je toestemming hebben gekregen. In plaats van gebruiker, device, connectiviteit, software en data is ook
In plaats van gebruiker, device, connectiviteit, software en data is ook 
 De feiten rondom big data zijn helder. Het datavolume groeit snel en op veel gebieden (denk aan de zorg) explosief. De toekomst biedt weliswaar geen feitelijke zekerheden, maar dat de groei sterk zal doorzetten valt niet te betwijfelen. Alleen al het mobiele dataverkeer neemt tot 2019 met 45 procent toe, aldus het laatste
De feiten rondom big data zijn helder. Het datavolume groeit snel en op veel gebieden (denk aan de zorg) explosief. De toekomst biedt weliswaar geen feitelijke zekerheden, maar dat de groei sterk zal doorzetten valt niet te betwijfelen. Alleen al het mobiele dataverkeer neemt tot 2019 met 45 procent toe, aldus het laatste 
 Nu
Nu  openbare infrastructuur als met andere auto’s. Het betekent dat er drie enorme datastromen op gang gaan komen: de eerste voor het besturen (de zelfsturende auto), de tweede voor het onderhoud (‘management’) en de derde voor aanvullende (commerciële) diensten. Voor het zelf rijden is een flinke hoeveelheid ‘sentrollers´ nodig – sensoren die kunnen waarnemen en signalen kunnen afgeven. Bij het zelfsturende auto is het niet zo zeer de motoriek van de automobilist, maar de menselijke waarneming die geëvenaard moet worden.
openbare infrastructuur als met andere auto’s. Het betekent dat er drie enorme datastromen op gang gaan komen: de eerste voor het besturen (de zelfsturende auto), de tweede voor het onderhoud (‘management’) en de derde voor aanvullende (commerciële) diensten. Voor het zelf rijden is een flinke hoeveelheid ‘sentrollers´ nodig – sensoren die kunnen waarnemen en signalen kunnen afgeven. Bij het zelfsturende auto is het niet zo zeer de motoriek van de automobilist, maar de menselijke waarneming die geëvenaard moet worden.