
Watson, de supercomputer van IBM en onovertroffen winnaar van Jeopardy, heeft een waardige opvolger naar het schijnt. Amelia – een virtuele agent – is een voortbrengsel van het New Yorkse bedrijf IPSoft en is gebouwd zoals ook de eerste succesvolle vliegtuigen zijn ontwikkeld: niet de bewegingen van een vogel nabootsen, maar de fysica van vleugels onderzoeken en toepassen. Amelia, zo bericht Wall Street Journal van 30 september, is al in 1998 ontwikkeld op basis van eigenschappen die de werking van het menselijk brein imiteren (cognitief computing). Amelia is genoemd naar de  vrouwelijke luchtvaartpionier Amelia Earhart. Ze wijkt in ieder geval sterk af van de persona’s die tot nu toe al worden ingezet en functioneren aan de hand van statische kennisbanken zonder leervermogen. Ook verschilt Amelia van ouder broertje Watson: Amelia wordt gevoed door nieuwe informatie die ze zelf toevoegt – dus niet door vooraf geprogrammeerde informatie. Watson is, net als de speciale Google zoekfunctie om katten te herkennen in YouTube video’s, een machine die aangedreven wordt door een zoekmachine gecombineerd met data-analyse. In Watson zijn geen cognitieve functies aangebracht.
vrouwelijke luchtvaartpionier Amelia Earhart. Ze wijkt in ieder geval sterk af van de persona’s die tot nu toe al worden ingezet en functioneren aan de hand van statische kennisbanken zonder leervermogen. Ook verschilt Amelia van ouder broertje Watson: Amelia wordt gevoed door nieuwe informatie die ze zelf toevoegt – dus niet door vooraf geprogrammeerde informatie. Watson is, net als de speciale Google zoekfunctie om katten te herkennen in YouTube video’s, een machine die aangedreven wordt door een zoekmachine gecombineerd met data-analyse. In Watson zijn geen cognitieve functies aangebracht.
Amelia is dus geen pratende, statische kennisbank. Vragen die ze niet herkent of begrijpt, zoekt ze zelf op: op het web of via een intranet van een bedrijf. Wanneer ze ook dan niet succesvol is, zet ze de vraag door naar een menselijke collega. Amelia moet wel getraind worden, maar dat geldt ook voor mensen. Een deel van het doorlopende leerproces bestaat uit het volgen van interacties tussen haar menselijke collega’s. Tijdens de eerste uitrol in een pilot slaagde Amelia er in om in een maand tijd zich zelfstandig te ontwikkelen van vrijwel onwetend tot een machine die onafhankelijk 42 procent van de meest gestelde vragen kon beantwoorden. In de tweede maand was dat opgelopen tot 64 procent.
Amelia is vooral goed in het oplossen van kennis-gebaseerde technische en feitelijke vraagstukken: zaken die goed in logica-gedreven stroomdiagrammen te vangen zijn en waarbij weinig subjectiviteit aan de orde is. Alles in kunstmatige intelligentie staat en valt met het kunnen voorspellen (op basis van grote hoeveelheden data) en het daarbij kunnen betrekken van de context; het kunnen werken met natuurlijke taal geeft Amelia hierin een voorsprong. Volgens IPSoft is Amelia in staat vragen met verschillende structuren, maar een identieke betekenis, als identiek te interpreteren. Met andere woorden, ze heeft verstand van syntaxis (zinsopbouw en woordvolgorde) en semantiek (betekenis).
Amelia wordt op dit moment getest op consistentie: leiden vragen die op verschillende manieren gesteld worden, maar die wel het zelfde probleem adresseren, ook op een correcte en consistente manier beantwoord? De bedoeling is dat Amelia op termijn het embedded brein wordt van Honda’s Asimo.
Is Amelia een bedreiging voor contactcenter agents? In het contactcenter wordt al volop ingezet op het zo veel mogelijk geautomatiseerd afhandelen van klantinteracties. We hadden al spraaktechnologie die dient voor herkenning en routering van klanten en hun vragen; ook met dynamische FAQ’s proberen contactcenters veel voorkomende vragen geautomatiseerd te beantwoorden. Amelia wordt, zo is het plan, binnenkort ingezet bij de customer service van Amerikaanse financiële instellingen, waarmee de automatisering in klantcontact weer een stukje opschuift. Volgens IPSoft zou Amelia in twintig talen kunnen functioneren en kan het contactcenter (in de Amerikaanse markt gaat 400 miljard dollar per jaar om) tot 75 procent op de kosten besparen, omdat 80 procent van de contacten repetitief van aard is – en dus is te automatiseren.
Is Amelia de eerste volwaardige virtuele assistent? In de wetenschap rondom robotisering en mens-machine interacties is de laatste tijd weer veel aandacht voor het fenomeen ‘uncanny valley’. Het begrip is geïntroduceerd door de Japanse robotexpert Masahiro Mori in de jaren zeventig van de vorige eeuw. Volgens Mori accepteren mensen bewegende en stilstaande robots tot op zekere hoogte maar slaat acceptatie om in afkeer als het onderscheid tussen robot en mens te klein wordt. Of de uncanny valley echt bestaat, is de vraag: er zijn onderzoeken die het fenomeen bevestigen en onderzoeken die het fenomeen onderuit halen. Uiteraard zullen robots (en kunstmatige figuren zoals in de film Avatar) zich blijven ontwikkelen, net als onze perceptie ten opzichte van dit soort figuren.
Het inbrengen van echte cognitieve en emotionele intelligentie in het dagelijkse werk is al moeilijk genoeg voor mensen, laat staan dat het goed in software te vangen is. Menselijke interactie in contactcenters zal noodzakelijk blijven voor klantcontacten waar emoties, gewetensvolle en strategische afwegingen, prioriteiten en complexe context moet worden meegenomen. Vergelijkbare dilemma’s doen zich voor bij de zelfrijdende auto. Overigens geeft haar fabrikant aan dat Amelia, die uiteraard in de cloud woont, ook emoties kan detecteren – iets dat ook al mogelijk is met geavanceerde taalherkenningssoftware, ingezet bij social media monitoring. Gecombineerd met het leervermogen heeft Amelia met emotiedetectie in ieder geval opnieuw een gedeelte van de exclusiviteit van menselijke competenties afgesnoept.


 Daar zijn twee nieuwe vijanden bijgekomen: big data en het Internet of Things. Het is de vraag wat de informatiespecialisten daar mee gaan doen. Vooralsnog weinig, afgaand op de KNVI-zoekmachine. Dat wordt straks schrikken voor die informatiespecialisten. Want de informatie-tsunami die veroorzaakt werd door web 1.0 en 2.0, wordt in een rap tempo opgevolgd door het veel grotere IoT.
Daar zijn twee nieuwe vijanden bijgekomen: big data en het Internet of Things. Het is de vraag wat de informatiespecialisten daar mee gaan doen. Vooralsnog weinig, afgaand op de KNVI-zoekmachine. Dat wordt straks schrikken voor die informatiespecialisten. Want de informatie-tsunami die veroorzaakt werd door web 1.0 en 2.0, wordt in een rap tempo opgevolgd door het veel grotere IoT.

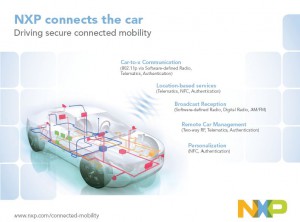 volledige garantie wanneer je de data die je auto genereert ter beschikking stelt aan derden – het automerk of de dealer. Die data werden normaal gesproken al uitgelezen tijdens onderhoudsbeurten, maar nu gaat dat 24/7 en real time. Die voorwaarde lijkt een nieuwe beperking van je privacy, maar op dat moment sta je er niet bij stil dat je gangen al gevolgd worden door camera’s boven snelweg en in de stad; en dat bij trajectcontroles naast je snelheid ook je identiteit, positie en tijd worden vastgelegd. Zonder dat je het weet, sta je tijdens je rit overigens al locatiegegevens af via je smartphone – rechtstreeks en via apps die daarvoor je toestemming hebben gekregen.
volledige garantie wanneer je de data die je auto genereert ter beschikking stelt aan derden – het automerk of de dealer. Die data werden normaal gesproken al uitgelezen tijdens onderhoudsbeurten, maar nu gaat dat 24/7 en real time. Die voorwaarde lijkt een nieuwe beperking van je privacy, maar op dat moment sta je er niet bij stil dat je gangen al gevolgd worden door camera’s boven snelweg en in de stad; en dat bij trajectcontroles naast je snelheid ook je identiteit, positie en tijd worden vastgelegd. Zonder dat je het weet, sta je tijdens je rit overigens al locatiegegevens af via je smartphone – rechtstreeks en via apps die daarvoor je toestemming hebben gekregen. In plaats van gebruiker, device, connectiviteit, software en data is ook
In plaats van gebruiker, device, connectiviteit, software en data is ook 