Veel gebruikers, veel interacties en veel cash is alles wat je nodig hebt om in een digitaal ecosysteem je slag te slaan. Als de wetgever je vervolgens toegang geeft tot informatie over – bijvoorbeeld – financiële transacties, ben je weer een stap verder. Over hoe grote technologiebedrijven zich steeds verder innestelen in ons leven.
Google heeft op de valreep van 2018 bekend gemaakt dat het in Litouwen en Ierland actief wordt met betaaldiensten. Hiervoor heeft het bedrijf een e-money-vergunning aangevraagd. Google krijgt met de Litouwse vergunning de mogelijkheid om in dat land volgens de nieuwe Europese PSD2-richtlijnen diensten aan te bieden, zoals het verwerken, beheren en faciliteren van financiële transacties. Onderdeel daarvan is het kunnen meekijken in de bankrekening van consumenten en betalingen uit hun naam doen, mits zij daar expliciete toestemming voor geven. Ook Apple, Amazon en Facebook hebben al eerder dit soort payment serviceprovider licenties verworven. Apple is sinds eind vorig jaar gestart met Apple Pay in Duitsland en België. Het FD constateert dat big tech zich klaarmaakt voor een actieve rol in de wereld van banktransacties. Volgens bankexpert Simon Lelieveldt zette Google overigens al in 2007 de eerste stappen.
Big tech en digitale ecosystemen
Deze beweging van big tech in de richting van onze (digitale) portemonnee past in een patroon. Big tech werkt gestaag aan de opbouw van op consumenten gerichte ecosystemen van diensten.
Nog geen drie jaar geleden voerde Tweakers Google, Apple en Microsoft op als belangrijkste platformspelers. Microsoft heeft intussen plaatsgemaakt voor Amazon, dat zich, net als bijvoorbeeld het Chinese Alibaba, voorbereidt op een positie op de Europese markt.
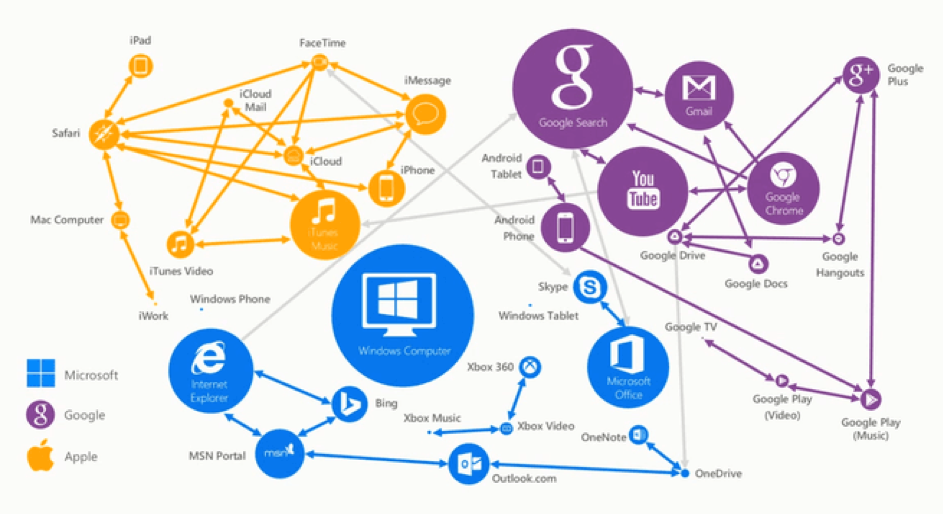
De ecosystemen van techreuzen zijn allemaal gebaseerd op verzamelingen van digitale platformen voor interacties en transacties. Zo’n ecosysteem nestelt zich op meerdere manieren in het consumentenleven in: het raakt vele facetten. Google heeft het Android besturingssysteem wat een dominante positie in de broekzak van consumenten oplevert. Daarnaast is Google al sinds jaar en dag marktleider in online zoeken en adverteren. Google wijst ons actief de weg, helpt ons met communiceren via Gmail en is op het vlak van videocontent marktleider met Youtube. Google Home Assistant is goed op weg om Siri van Apple te verslaan; de populaire Alexa van Amazon begrijpt nog geen Nederlands.
De ecosystemen van Amazon en Apple zijn weliswaar minder breed van karakter, maar net als Google beschikken ze over platformtechnologie, voldoende volume (klanten en gebruikers) en voldoende cash. Volume (aan gebruikers en interacties) en cash is alles wat je nodig hebt om in een ecosysteem je slag te slaan. Je zou kunnen zeggen dat een platform alleen niet meer voldoende is. Platformen waar vraag en aanbod samenkomen, zijn gemakkelijk te kopiëren. Denk aan Airbnb dat de hete adem van Booking.com voelt. Een retailer als bol.com kiest bewust voor een platformstrategie, maar is voor toekomstig succes afhankelijk van een plek in een ecosysteem.
Wie bouwt aan welk ecosysteem?
Wanneer je kijkt naar de positie van Google, dan lijkt dat bedrijf een voorsprong te hebben. Google weet waar je naar zoekt en hoe je omgaat met welke informatie. Dat zegt iets over je opvattingen. Met Google Shopping en met Reviews kan aankoopgedrag worden gestuurd. Google weet waar je woont en waar je naar toe wil. Op basis van locatie en snelheid weet Google ook op welke wijze je je verplaatst. Ook binnenshuis weet Google steeds vaker ook in welk vertrek je bent, bijvoorbeeld door Google Home, die je stem herkent en de vijf basisemoties kan afleiden. Google kan afleiden wie je familie is, waar deze woont en waar je werkt. Genoeg context voor uiteenlopende financiële diensten.
Geen enkel ecosysteem is hetzelfde qua samenstelling en omvang en Google mag dan een voorsprong hebben, het bedrijf mist nog wel een aantal onderdelen. Zo heeft Google nog geen toegang tot informatie over onze voeding, beweging, slaap en gezondheid. Daar is Apple weer beter in. Dat Apple een hardwareontwikkelaar is met een enorme marge en een goed gevulde oorlogskas, geeft het bedrijf alle mogelijkheden om een plek te verwerven in het zorgecosysteem.
Google heeft ook – met hoofdzakelijk Gmail – relatief weinig vat op onze dagelijkse communicatie. Op dat vlak heeft Facebook als sociaal netwerk en als eigenaar van WhatsApp de beste kaarten in handen. En Amazon wint het als het gaat om een voorsprong in online retail, maar legt het nu nog af als het gaat om de interactie met klanten. Begrijpelijk dat ook Amazon inzet op een spraakgestuurde assistent.
Wat ontbreekt er nog in het portfolio van Google? Net als de andere big tech spelers heeft het bedrijf nog geen platform voor arbeid of inkomensverwerving. Alleen Uber heeft als techspeler een rol in de gig economy, maar bemiddelt tot nu toe alleen in logistiek werk (transport van mensen en van voedsel). Met een mondiaal groeiende middenklasse verandert ook de markt voor arbeidsbemiddeling. Online arbeidsplatformen omvatten inmiddels veel meer dan alleen klusplatformen voor laagbetaald werk zoals Uber, Deliveroo en Helpling. De markt voor platformen die hoogwaardig en gespecialiseerd werk aanbieden (zoals Upwork, Toptal en Catalant) groeit elk jaar met 30 procent.
Ecosysteem voor iedere sector
Big tech heeft ook nog weinig greep op de energiesector. Dat is vreemd, want wereldwijd zijn Google (3 GigaWatt), Facebook (2 GigaWatt) en Apple Amazon en Microsoft (elk 1 GigaWatt) grootverbruikers van groene stroom, waarbij ze investeringen in duurzame, herwinbare energie afdwingen. Het stroomverbruik van big tech steeg in 2018 ten opzichte het jaar ervoor met 10 GigaWatt. Maar big tech neemt zelf geen energiebedrijven over en komt evenmin met duidelijke proposities op het gebied van decentrale opwekking – zoals Tesla heeft geprobeerd met de Power Wall en energieoplossingen voor bedrijven.
Een vergelijkbare situatie doet zich voor in sectoren als toerisme, huisvesting, verzekeringen of levensmiddelen. Wanneer big tech spelers besluiten in zo’n sector toe te slaan, zal de impact waarschijnlijk enorm groot zijn. Denk aan Apple dat een aantal zorgverzekeraars overneemt, aan Amazon dat Unilever in zijn geheel opslokt, of aan Google dat wereldwijd met PSD2 aan de slag gaat. In dit soort scenario’s geldt winner takes all.
Voorlopig lijkt big tech vooralsnog relatief bescheiden overnames te doen met een beperkte ‘disruptieve impact’. Enkele voorbeelden van de afgelopen jaren: Apple nam Beats by Dr Dre over en Microsoft kocht Linkedin op (goed bruikbaar als groot zakelijk netwerk) en nam Skype over, wat goed aansloot op Office 365.
Maar de overnames van Amazon lijken anders van karakter. Niet alleen nam Amazon de Amerikaanse supermarktketen Wholefoods over, het bedrijf besloot ook om 40 Boeings 767 te gaan leasen. Daarmee wordt Amazon minder afhankelijk van logistieke dienstverleners zoals FedEx en UPS (die samen ruim 900 vliegtuigen in de lucht hebben). Amazon Pay, alles wat nodig is om betalingen te kunnen afwikkelen, wordt overigens ook al buiten de eigen webwinkel ingezet. Daarnaast biedt Amazon al renteloze leningen aan Europese klanten aan. In de zomer nam Amazon al een grote online apotheek over. Of vanuit een ander perspectief: Amazon beheert én een steeds groter deel, én steeds meer schakels in de keten van consumentenbestedingen.

Big tech doet wat ze wil
Dit patroon, waarbij big tech ecosystemen uitbouwt, baart Europese politici en bedrijven uiteraard zorgen. Dat is begrijpelijk, want Europa speelt geen rol in big tech. Europa is primair toeschouwer en probeert de macht van big tech te beteugelen via wet- en regelgeving. Of dat voldoende is om een pluriforme economie in stand te houden, is de vraag. Want “big tech doet wat ze wil. De ene keer bouwen ze iets zelf, de andere keer zoeken ze de samenwerking.” (…) “Apple, Google en Facebook hebben geen interesse in de transactie, maar in de data,” aldus het FD.

















 Amsterdam ziet data ook als de sleutel tot het aanpakken van het vraagstuk van bijna
Amsterdam ziet data ook als de sleutel tot het aanpakken van het vraagstuk van bijna