
Door digitalisering worden in veel bedrijven processen steeds complexer. Dat maakt de rol van toezichthouders – commissarissen, accountants, auditors – lastiger. De toepassing van algoritmen die op basis van machine learning werken, vergroot deze uitdaging. Ook auditors maken tegenwoordig gebruik van slimme systemen om andere slimme systemen te controleren. Wie controleert wat?
 Yuval Harari, auteur van 21 Lessons for the 21st Century, is ervan overtuigd dat in de toekomst ons brein wordt gehacked door kunstmatige intelligentie. Hij verwacht dat biotechnologie en kunstmatige intelligentie naar elkaar toe zullen groeien en vraagt zich af wie deze ontwikkeling aanstuurt en bepaalt. Zijn dat burgers, overheden of juist de grote bedrijven? Het antwoord laat zich raden. Overheden zullen ontwikkelingen op dit snijvlak vooral aangrijpen voor nationale belangen zoals defensie en daarnaast liggen de mogelijkheden bij bedrijven, niet bij burgers.
Yuval Harari, auteur van 21 Lessons for the 21st Century, is ervan overtuigd dat in de toekomst ons brein wordt gehacked door kunstmatige intelligentie. Hij verwacht dat biotechnologie en kunstmatige intelligentie naar elkaar toe zullen groeien en vraagt zich af wie deze ontwikkeling aanstuurt en bepaalt. Zijn dat burgers, overheden of juist de grote bedrijven? Het antwoord laat zich raden. Overheden zullen ontwikkelingen op dit snijvlak vooral aangrijpen voor nationale belangen zoals defensie en daarnaast liggen de mogelijkheden bij bedrijven, niet bij burgers.
Dat hacken van ons brein is een goed voorbeeld van de tegenstrijdige wereld waar we naar toe gaan: technologie kan problemen oplossen en onze levens verbeteren, maar per saldo krijgen we steeds minder vat op ons leven. Hoe groter de rol van kunstmatige intelligentie wordt, hoe minder onze eigen hersenen een bepalende rol blijven spelen.
Wie controleert de werking van software
 Wat ons mogelijk te wachten staat, laat het meest recente debacle van ING zien: de witwas-affaire. Bij banken is uitgebreide monitoring van transacties verplicht volgens de wet ter voorkoming van witwassen en financieren van terrorisme. Voor een grootbank is dat monitoren een proces dat ingericht en uitgevoerd wordt met behulp van software, die doorlopend grote hoeveelheden data moet analyseren. Deze software programmeer je in eerste instantie natuurlijk om het proces dat de wet voorschrijft, uit te voeren. Hierbij worden zowel medewerkers als beslissers voorzien van feedback uit systemen: beslissingen op bestuursniveau worden genomen op basis van data. Of die systemen integer zijn ontwikkeld en doelmatig functioneren (doen waarvoor ze zijn ontworpen) is niet gemakkelijk te zien, laat staan doorlopend zichtbaar. Toetsing door middel van interne en externe audits moet aantonen dat de software zijn werk goed doet en dat de software ook goed wordt ingezet. Bij ING was ergens in dit monitoringproces besloten om de software aan te passen. “Het systeem om transacties te monitoren was – mede vanwege de beperkte personele capaciteit – door de bank zo ingesteld dat slechts een beperkt aantal witwassignalen werd gegenereerd”, aldus het Openbaar Ministerie.
Wat ons mogelijk te wachten staat, laat het meest recente debacle van ING zien: de witwas-affaire. Bij banken is uitgebreide monitoring van transacties verplicht volgens de wet ter voorkoming van witwassen en financieren van terrorisme. Voor een grootbank is dat monitoren een proces dat ingericht en uitgevoerd wordt met behulp van software, die doorlopend grote hoeveelheden data moet analyseren. Deze software programmeer je in eerste instantie natuurlijk om het proces dat de wet voorschrijft, uit te voeren. Hierbij worden zowel medewerkers als beslissers voorzien van feedback uit systemen: beslissingen op bestuursniveau worden genomen op basis van data. Of die systemen integer zijn ontwikkeld en doelmatig functioneren (doen waarvoor ze zijn ontworpen) is niet gemakkelijk te zien, laat staan doorlopend zichtbaar. Toetsing door middel van interne en externe audits moet aantonen dat de software zijn werk goed doet en dat de software ook goed wordt ingezet. Bij ING was ergens in dit monitoringproces besloten om de software aan te passen. “Het systeem om transacties te monitoren was – mede vanwege de beperkte personele capaciteit – door de bank zo ingesteld dat slechts een beperkt aantal witwassignalen werd gegenereerd”, aldus het Openbaar Ministerie.
In dit verhaal valt op dat het besluit dat ING nam om een systeem aan te passen, intern niet werd afgekeurd (zowel het nemen van het besluit als het aanpassen van het systeem was mensenwerk). Ook is bijzonder dat de auditors die processen en systemen moeten controleren, de aangepaste instellingen van een cruciaal systeem niet hebben gezien – of gemeld.
Wat zijn de intenties van de bedenkers van algoritmen
De processen en systemen die auditors moeten controleren worden steeds ingewikkelder. Die systemen gaan steeds vaker gebruik maken van algoritmen – uitgebreide instructies voor software om een bepaald doel te bereiken, zoals het herkennen van verdachte financiële transacties. In dit soort complexe processen moeten zowel de instructies als de uitkomsten en de benodigde grondstof (data) aan allerlei eisen voldoen. De data moeten betrouwbaar zijn (niet vooraf gemanipuleerd), de instructies moeten voldoende uitputtend en effectief zijn.
Daarnaast moet helder zijn op basis van welke uitgangspunten de algoritmen zijn opgesteld (kostenreductie, risicominimalisatie, wantrouwen, voldoen aan regels). Zo kan een verzekeraar voor de acceptatie van nieuw klanten een algoritme ontwikkelen dat bepaalde klanten uitsluit, omdat ze een te groot risico vormen. Het uitsluiten van een nieuwe klant gebeurt echter niet op basis van feitelijke kenmerken van de klant, maar van een profiel waarbij niet gecontroleerd wordt of die klant ook voldoet aan het profiel. Kortom, wie bewaakt dat uitzonderingen ook als uitzonderingen worden behandeld?
Systemen die op basis van algoritmen draaien, nemen hoe dan ook beslissingen, waarbij de bestuurder en de toezichthouder ‘toekijken’; het is aan de auditor om het geheel met enige regelmaat door te lichten om na te gaan of alles werkt zoals het zou moeten werken.
Controle en audit
Interne controles worden in bedrijven uitgevoerd om te voorkomen dat door onvolledige of incorrecte gegevens een onjuist beeld ontstaat, waardoor verkeerde beslissingen genomen zouden kunnen worden. In eerste instantie is die controle erop gericht om te zorgen dat het management op basis van juiste gegevens beslissingen neemt. In tweede instantie worden zo ook de gegevens gecontroleerd die een bedrijf naar buiten brengt. Omdat – onder meer door het Enron-schandaal – duidelijk werd dat ook doorlopend onderzoek naar de beheersing van de ICT onderdeel moet uitmaken van de controle van de verantwoording door de directie van de onderneming, zijn de regels voor verantwoording uitgebreid met Sarbanes-Oxley (SOX) en Basel II. SOX schrijft bijvoorbeeld voor dat met bewijs onder meer wordt verantwoord welke software is aangepast, waarom en door wie.
Software wordt dynamisch
Auditors controleren onder meer software, al jarenlang. Die software was tot nu toe redelijk statisch van aard, veranderingen of ‘changes’ worden in de wereld van IT bovendien zorgvuldig afgewogen, ontworpen, getest en gedocumenteerd. Met de komst van kunstmatige intelligentie verandert dit. Want bij machine learning, de meest impactvolle vorm van kunstmatige intelligentie, evolueert software zonder menselijke tussenkomst. De software heeft een eigen feedback-loop en leert doorlopend van nieuwe data. “Hoe weet je dan nog of de algoritmes doen wat ze horen te doen? Hoe kun je vertrouwen hebben in zo’n zelflerend systeem?”, aldus Mona de Boer, expert op het gebied van data-analyse en digitale assurance bij PwC Nederland.
Het werk van auditors gaat dus steeds meer bestaan uit het analyseren en controleren van algoritmen. Tegelijkertijd maken auditors zelf ook in toenemende mate gebruik van algoritmen. GL.ai is een robot, ontwikkeld en ingezet door PwC, die met kunstmatige intelligentie in staat is miljarden verschillende gegevenspunten in seconden te analyseren bij het beoordelen van afwijkingen in grootboektransacties. Hoe langer GL.ai aan het werk is, hoe slimmer deze robot wordt. We gaan dus toe naar een situatie waarbij algoritmen hun collega-algoritmen gaan controleren. Dat plaatst het toezicht in een bijzonder perspectief. Toezicht was tot nu toe gericht op verantwoordingsdocumentatie: kan een bedrijf aan de hand van vastgelegde afspraken (wie doet wat, wie heeft wat gedaan) uitleggen hoe resultaten tot stand zijn gekomen?
Uitlegbaarheid algoritme
De Boer waarschuwt dan ook voor de ontwikkeling dat systemen steeds slimmer, maar gelijktijdig ook steeds minder goed uitlegbaar worden – want los van de ontwerpbeginselen zijn de systemen zelf veranderlijk. Mensen hebben de neiging om beslissingen die door een computer worden genomen, te beschouwen als beter en meer betrouwbaar dan beslissingen die door mensen worden genomen. Ook algoritmen worden, net als technologie, al snel beschouwd als ‘neutraal’. Maar technologie en software 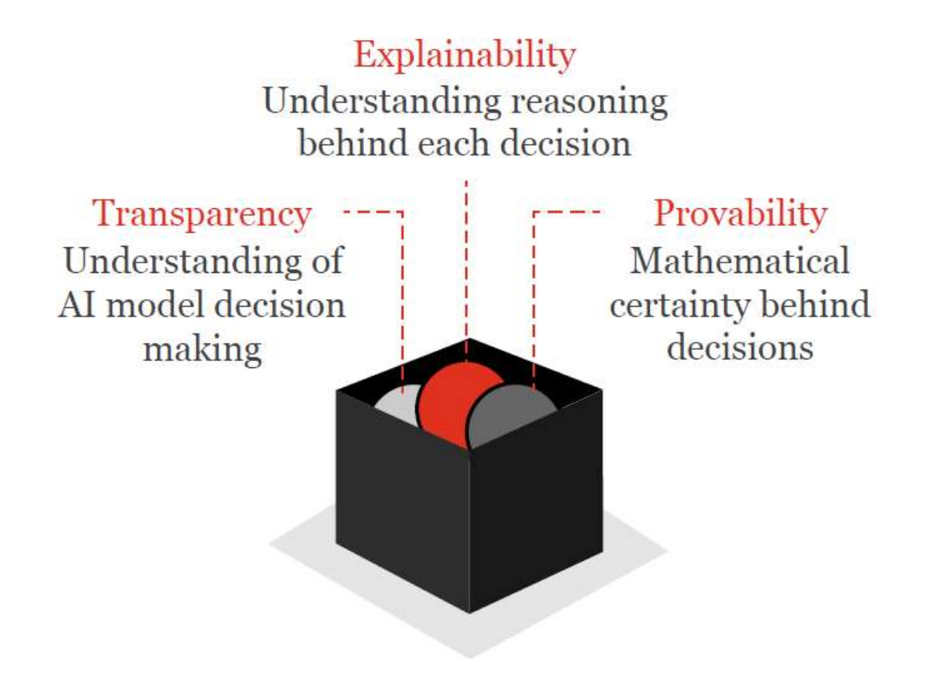 zijn niet neutraal – de werking moet beslist niet in het nadeel, maar in het voordeel van de bedenker werken. Daarnaast maakt het vermogen van kunstmatige intelligentie om zichzelf verder te kunnen ontwikkelen de controleerbaarheid erg lastig. De Boer pleit dan ook voor ‘uitlegbaarheid’ als ontwerpprincipe van AI.
zijn niet neutraal – de werking moet beslist niet in het nadeel, maar in het voordeel van de bedenker werken. Daarnaast maakt het vermogen van kunstmatige intelligentie om zichzelf verder te kunnen ontwikkelen de controleerbaarheid erg lastig. De Boer pleit dan ook voor ‘uitlegbaarheid’ als ontwerpprincipe van AI.
De keerzijden van machinelearning
Die uitlegbaarheid gaat bijvoorbeeld over welke datasets worden gebruikt en welke criteria worden gebruikt. Evert Haasdijk (AI-specialist en senior manager Financial Advisory bij Deloitte) geeft een goed voorbeeld. Uit databaseonderzoek blijkt dat de meeste schade wordt veroorzaakt door bestuurders van rode auto’s. Met datamining kun je dus op kleur van auto’s premies differentiëren. Haasdijk wijst op de vraag of bij het ontwikkelen van het algoritme een juiste dataset is gebruikt: “Zitten er bij die rode auto’s niet een paar Ferrari’s die de schadelast enorm hebben opgeschroefd? Heel veel modellen kloppen gewoon niet. Het is natuurlijk onzin dat mensen in rode auto’s slechtere bestuurders zijn.”
Belangrijke eigenschap van machine learning is dat nieuwe afwijkingen of uitzonderingen niet direct leiden tot andere uitkomsten. Machine learning is een geleidelijk leerproces. Net als bij het menselijk brein levert ieder nieuw voorbeeld een kleine bijdrage aan nieuwe logische verbindingen.
 En tot slot is het interessant dat we al sinds de opkomst van het sociale web de basis leggen voor een toekomst waarin machine learning alle ruimte krijgt. Onze digitale samenleving bestaat inmiddels voor een groot deel uit het produceren en afstaan van data, iets waar de Chinese president Xi Jinping handig gebruik van wil maken. Vervang ‘China’ door ‘een bedrijf’ en het is duidelijk dat kunstmatige intelligentie straks voor onuitlegbare verschillen kan gaan zorgen tussen mensen. Vrijwel alle bedrijven zitten al op een berg aan data en dat volume neemt alleen maar toe. Die data zijn in het verleden ‘afgestaan’ volgens wetten en regels uit dat verleden, maar ook met de technologische mogelijkheden uit die tijd. Werk aan de winkel dus voor bestuurders en toezichthouders om zicht en grip te houden op hoe hun organisatie op basis van nieuwe technologie met zowel reeds eerder verzamelde als nieuwe data omgaat. Een mooie, maar wellicht wat romantische houvast komt van journalist en Wall Street Journal R&D chief Francesco Marconi: “Algorithms are rules, and those should be fair.”
En tot slot is het interessant dat we al sinds de opkomst van het sociale web de basis leggen voor een toekomst waarin machine learning alle ruimte krijgt. Onze digitale samenleving bestaat inmiddels voor een groot deel uit het produceren en afstaan van data, iets waar de Chinese president Xi Jinping handig gebruik van wil maken. Vervang ‘China’ door ‘een bedrijf’ en het is duidelijk dat kunstmatige intelligentie straks voor onuitlegbare verschillen kan gaan zorgen tussen mensen. Vrijwel alle bedrijven zitten al op een berg aan data en dat volume neemt alleen maar toe. Die data zijn in het verleden ‘afgestaan’ volgens wetten en regels uit dat verleden, maar ook met de technologische mogelijkheden uit die tijd. Werk aan de winkel dus voor bestuurders en toezichthouders om zicht en grip te houden op hoe hun organisatie op basis van nieuwe technologie met zowel reeds eerder verzamelde als nieuwe data omgaat. Een mooie, maar wellicht wat romantische houvast komt van journalist en Wall Street Journal R&D chief Francesco Marconi: “Algorithms are rules, and those should be fair.”
Dit artikel is ook doorgeplaatst op iBestuur